

En förstudie som undersöker befintliga tjänster samt utvecklarnas hantverk för att uppnå machine intelligence.
Uppdatering 2020: Nu är AI för bättre hälsa släppt, en nationell rapport som kompletterar denna förstudie.
Författare: Marcus Österberg
Redaktör: Lars Lindsköld
Version: Webbversion 1.0
Släppt: 2018-06-06
Copyright: Ingen / CC0, exklusive bilder
Licens: Allmän handling
Ladda ner som ebok hos:
Innehållsförteckning
- Sammanfattning
- Bakgrund till artificiell intelligens (AI)
- Vad menas med “intelligens”?
- AI är inte bara en sak, men för det mesta är det machine learning som avses
- Träna upp neurala nätverk för att efterlikna en hjärna
- Deep learning orsaken till förnyat intresse i AI
- En självinstruerande maskin? Supervised vs Unsupervised vs Reinforcement vs Transfer!
- Att skapa en maskin med minne för detaljer?
- Vad är bra nog som resultat för machine learning?
- Styrkor som talar för machine learning
- Vad är bristerna idag? Toy problems, bland annat!
- Vad vi undersökt
- Resultat
- Slutsats – vad vill vi göra framåt?
- Appendix
Sammanfattning
Nedan följer en sammanfattning av våra tre hypoteser, vad vi undersökt och tankar framåt. Vår avsikt har varit att undersöka leverantörernas erbjudande samt att få koll på hur man går tillväga för att göra grundjobbet själv.
Vi kan redan här konstatera att det inte är artificiell intelligens (AI) vi jobbat med utan snarare machine learning (ML). De personer som verkar se nyktert på hajpen kring AI tycks vara eniga om att ML visserligen är ett delområde inom AI, i akademiska kretsar, men att vi kommer få vänta minst några årtionden till innan vi har en meningsfull AI. Så i rapporten kan vi möjligen relatera till den förhoppning som finns med AI i framtiden men vi vill vara tydliga med att vi anser att machine learning är ett mycket lämpligare begrepp för var teknikutvecklingen står idag. Möjligen att även machine intelligence, som används en del i akademiska sammanhang, sätter rätt förväntningar.
Hypotes 1: bearbeta och förstå anamnes och patientberättelser
Först behöver vi göra åtskillnad på begreppen anamnes och patientberättelse. Med anamnes avses i denna rapport den av vårdpersonal inskrivna sjukdomshistorien, visserligen lämnad av patienten vid vårdtillfället, men det är ett styrt samtal med ett mål om att få en bra helhetsbild så som vi i vården vill strukturera historien för att ge bakgrunden till det vi kommer att göra. En patientberättelse däremot är så som man berättar det mer spontant och i andra sammanhang. Anledningen att vi behöver göra skillnad beror på att vi i vården har mängder med anamnes kopplade till besök. När det gäller berättelser kan det lika gärna vara en app i form av en hälsodagbok, eller så som de utan styrning skulle logga sin hälsa. Anamnes kan sägas vara information given vid en viss tidpunkt och individens berättelse blir information som täcker in en tidsperiod.
Genom tekniken naturlig språkförståelse, NLP (Natural Language Processing), kan vi plocka ut vad en person pratar om, och vad de har för symptom (genom NER, Named Entity Recognition). På så vis kan vi slå upp mot medicinska kodverk, vårdplaner och riktlinjer vad som är en lämplig aktivitet. Under förstudien har vi främst matchat anamnes från thorax mot kodverket ICPC (International Classification of Primary Care). Men metoden kan naturligtvis användas med andra kodverk som används, till exempel Snomed CT, ICD-10 och KVÅ.
När vi utvärderat Amazons AWS-tjänst för NLP hälsar den vänligt men bestämt att den inte stödjer svenska, och vi är inte trygga med att automatiskt översätta utan att förlora eller förvanska information.
Men att göra NLP mer manuellt (och på svenska) verkar vara görbart genom ramverk som NLTK (Natural Language Toolkit) samt att man kan bearbeta det man fått fram med andra tekniker inom machine learning, exempelvis deep learning.
Slutsats
En stor utmaning är avsaknaden av strukturerad information om diagnoser, medicinska riktlinjer och liknande som kan förstås av en maskin. Om den typen av information vore maskinläsbar istället för som PDF-filer, och att maskiner kunde utforskas så som vi människor kan utforska Wikipedia, skulle vi kunna åstadkomma mycket mer. Detta görs med en teknik kallad länkade data. Några som förstått detta är Socialstyrelsen med sitt API Försäkringsmedicinskt beslutsstöd.
En lovande avhandling presenterades på Chalmers under våren och handlar om att summera medicinska texter. Av vår psykiatriverksamhet har vi förstått att det skulle vara extremt attraktivt som lösning då deras patientjournaler tenderar att vara mycket långa och praktiskt taget omöjliga att läsa igenom ordentligt inför varje besök.
Hypotes 2: röst- och konversationsbaserat användargränssnitt
Att enbart förlita sig på en röstbaserad konversation som gränssnitt verkar idag inte möjligt, på svenska. Det blir ofta missuppfattningar och frågan är om man vinner något om användaren manuellt behöver rätta det som talats in. Vi har främst testat Apples SiriKit samt Microsofts Azure. Azure förstod inte vad vi sa ens när vi valt att läsa upp en viss replik från Gudfadernfilmerna, inte ens efter tre försök, trots att den visste vilken repliken var. Visserligen gjordes testet i en stökig miljö, men det är nog inte en orimlig ljudbild för ett realistiskt användarscenario, tycker vi.
Vi har också utvärderat de smarta högtalarna Google Home och Amazons Alexa för att tänka in vilken utrustning en användare skulle kunna ha hemma när de behöver komma i kontakt med vården i framtiden. Dessa två talar inte svenska, men för några av landets mindre språk kan liknande prylar bli relevanta snabbare än för majoriteten av svenskar.
Det vi lärt oss från testerna med röststyrda prylar är att de är fantastiska för de som av en eller annan anledning har svårt att skriva, stava eller läsa, men kan tala alldeles utmärkt.
“En vanlig bedömning är att 5–8 procent av befolkningen i den läskunniga delen av världen har läs- och skrivsvårigheter av dyslektisk art.”
– Svenska Dyslexiföreningen
Och ärligt talat, även vi som inte har svårigheter kämpar nog ibland med ord vi inte är vana vid att se i skrift men vet vad det heter. Ett konversationsbaserat, eller röststyrt, gränssnitt kan göra vården mer tillgänglig för de med funktionsnedsättningar.
Slutsats
Vår slutsats är att man med fördel erbjuder både tal och tangentbord när text ska matas in. När tal används behöver man dock få chansen att rätta texten innan den skickas, används eller lagras.
Hypotes 3: Computer Vision och deep learning
Att använda de stora molnleverantörernas färdiga tjänster för en meningsfull bildigenkänning inom medicinen tycks omöjligt. Vi har särskilt utvärderat Microsofts Azure och Amazons AWS. Röntgenbilder på händer beskrivs som “A white vase on a table”. En man tillbakalutad på brits som får spruta i armen taggas som “person, indoor, sitting, using, woman, holding, bed, table, hand, top, green, young, white, cutting, food, man, playing” där ”using” möjligen förklarar sprutan trots att vi hellre sett taggen “syringe”.
Slutsats
Dock kan vi alltid backa tillbaka och göra grovjobbet själva. Då handlar det om att maskinellt dokumentera geometrin bakom en dålig leverfläck, eller vad man nu vill identifiera. Detta verkar främst göras med att jobba fram modeller så man maskinellt kan upptäcka saker (feature detectors) och jobba med neurala nätverk (troligen av sorten convolutional). Det är ett tänkbart spår för en fortsättning.
Sammanfattat
Vi kan dessvärre konstatera ett antal hinder:
- Att svenska inte är ett prioriterat språk vilket gör det svårt att jobba med NLP eller att köpa in tjänster. Möjligen kommer vissa av våra minoritetsspråk att få stöd innan det kommer för svenska.
- Att medicinskt innehåll inte känns igen i de färdiga lösningarna hos de stora leverantörerna.
- Det finns få färdiga produkter att köpa in, eller hyra, som är användbara till något meningsfullt. Ganska ofta hänvisas det till en osäkerhet om ansvaret samt att leverantörerna fortfarande inte riktigt bestämt sin affärsmodell (kanske för att det är lite oklart var det största värdet finns).
Det vi kan använda de stora molnleverantörerna Amazon, Google och Microsoft till är att hyra beräkningskraft för att träna våra egna modeller inom machine learning. Färdiga lösningar tycks de inte ha (ännu), åtminstone inte inom ett medicinskt användningsområde.
NLP är mest lovande
Mest lovande för en fortsättning är beslutsstöd vid egenvård/självtriage, samt att skapa olika informationstjänster baserade på individens besvär. Triage är en metod för att sortera och prioritera patienters behov baserat på deras anamnes, symtom och ibland data om puls, andning, kroppstemperatur, etc. På en akutmottagning är det vanligen den första bedömningen du får innan du antingen får vänta på din tur eller som i akuta fall kommer först i kön.
Anamnes är intressant i kombination med NLP-teknik eftersom vi då kan matcha anamnes mot medicinska vokabulär som SnoMED-CT, ICD-10, ICPC med flera. Det ger en ökad struktur på fritext och kan då bättre komplettera övriga data när vi tränar upp ett neuralt nätverk.
Vår bedömning är att de ML-funktioner som finns för enkel användning på molnleverantörernas tjänster inte är redo för en meningsfull användning av bilder ännu. Inte heller stöds svenska som språk vid NLP, med IBM som undantag där tre av nio NLP-funktioner stöds även på svenska.
Med andra ord behöver vi själva ta ett större tekniskt ansvar om vi ska få ML att hända, alternativt så väntar vi och hoppas på att någon annan löser våra problem åt oss. Men att använda samma teknik som är tillgänglig för resten av världen kanske inte ger en topplacering inom världens ehälsa till 2025? Kanske måste vi göra mesta möjliga av vår egen unika kompetens, både det tekniska samt vårdande?
Omvärldskoll på Vitalis-konferensen 2018
Lite nedslående är att ingen av de lösningar som visats upp som AI under Vitalis 2018 verkar ha kommit så långt att de går att använda. Dels tycks de bygga på massor med manuellt strukturerad information, i form av triageprotokoll, eller beslutsträd för dig som är tekniskt lagd, för att ha en kunskapsmassa, men också att man inte ens använt etablerad teknik för att låta maskinen ha en kontextuell förståelse.
Ett exempel på en AI-sjuksköterska föreslog “svamp i underlivet” som relevant fortsatt konversation på besväret “nagelsvamp”. En förhållandevis enkel lösning kring olika begrepps relation skulle kunnat stödja AI-sjuksköterskan att nagel och underliv inte är nämnvärt besläktade.
Nästa steg – fler involverade
Mer positivt är att vi har knutit kontakt med en läkare på Sahlgrenska som delar vår bild om fortsättning och vi behöver nu hitta resurser för en mer storskalig utvärdering som är närmre vårdverksamheten. Samtidigt vet vi att det finns ett förstudieprojekt inom VGR:s omställningsområde Digitala vårdtjänster som syftar till självtriage. Självtriage är ett tänkbart resultat av en sån här satsning, en annan är en automatiserad second opinion och kvalitetsarbete i största allmänhet då det blir förhållandevis enkelt att hitta avvikelser där diagnosen är oväntad i relation till innebörden av anamnes, eller labbsvaret.
Vi har uppvaktats av Chalmers innovationskontor och planerar för en gemensam fortsättning med en NLP-forskare från dem.
Med tanke på vad vi lärt oss om möjligheterna med deep learning och de mängder med patienthistorik vi har verkar en kombination av NLP och deep learning det vi bör fokusera på i ett mer storskaligt projekt.
Vi hoppas kunna sammanföra flera parters intressen med ett gemensamt nästa steg, nära vårdverksamheten, så det blir verkstad och omställning i verkligheten!
Resultatet av detta förstudieprojekt är stora drag klart nu. Vi har hittat ett fokus och har för avsikt att utveckla det genom att söka medel från innovationsfonden för 2019, samt att vi även kommer leta efter annan projektfinansiering.
Bakgrund till artificiell intelligens (AI)
Utan att diskutera AI som begrepp i några längre ordalag avser vi med det begreppet i denna rapport så kallad snäv AI (weak eller narrow AI). Det vill säga en specialiserad, icke-generell, AI. En maskin som gör en sak bra men inte alls begriper andra saker den inte stött på. Man kan också välja att se AI som ett forskningsområde där machine learning är huvudnumret. I realiteten är det snarare machine learning vi håller på med i denna förstudie.
Eftersom nästan allt kallas för AI idag är det svårt att hitta guldkornen i det som erbjuds. Därför blev vi intresserade av en förstudie för att undersöka vad av det som är “färdigt” och paketerat inom AI som vi kan dra nytta av. Med andra ord eftersträvar vi att använda det som redan är gjort på det som är ogjort, det vill säga matcha vad leverantörer på olika nivåer har och applicera på våra datakällor.
Men vad menas med AI? En vettig definition av AI är den som nedtecknades på 1950-talet, nämligen:
”the capability of a machine to imitate intelligent human behavior”
Vad menas med “intelligens”?
”Och dessutom lovar marknadsföringen betydligt mer än vad den kan hålla även när det gäller äkta artificiell intelligens.”
– Svårt för it-köpare att hitta rätt när allt kallas för AI (Computer Sweden)
Ett sätt att mäta artificiell intelligens är Turingtestet. Då ska en människa bedöma om den pratar med en maskin eller människa. Men man kan också diskutera vad man menar med ordet “intelligence”. Översätter man det rakt av till svenskans “intelligens” kommer man ofta bli besviken på det AI lyckas utföra 2018. Men om man istället jämför det med hur “intelligence” ingår i andra begrepp eller områden, som Business Intelligence (BI) blir innebörden en helt annan.
Men fler nyanser finns om man kollar in vad en ordbok säger:
”The ability to acquire and apply knowledge and skills.”
Ja, en AI kan genom machine learning lära sig saker baserat på de data den matas med.
Man kan diskutera vad man menar med “apply”, men visst. Att applicera sin kunskap kan vara i linje med de som menar att en AI måste ha en kropp eller annan representation, uppnått medvetande, samt vara dödlig, för att vara intelligent på riktigt. I sin mest banala form kan man också argumentera för att en kakstämpel som massproducerar pepparkaksgubbar applicerar sin kunskap.
Men vad menas med “skills”? Är det att den kan säga ifrån att den inte kan dra slutsatser baserat på underlaget, eller att den inte tycker att det den lärt sig kan appliceras på den fråga den fått? Det vi fiskar efter med detta resonemang är att intelligens kanske kräver mer än enbart gammal hederlig beräkningskraft.
”The collection of information of military or political value” och ”the gathering of intelligence”
Här kommer vi in på likheten mellan AI och Business Intelligence. Att det mer handlar om vetskap, kännedom och insikt genom information. Den här definitionen av AI har vi i projektet vissa problem med. Om “intelligens” på svenska skulle handla om insamlandet av data så borde vi rimligen inte ha någon brist på AI-kompetens med tanke på att detta är vad varje databasadministratör (DBA), många backend-utvecklare och alla fullstack-utvecklare gjort under majoriteten av sina karriärer.
Oavsett vad man anser att en AI är, eller hur man definierar intelligens, är en maskin inte jämförbar med en människa. AI kan förväntas ha mänskliga förmågor, men dess beräkningskraft har varit omänsklig sedan mycket länge. Sätt en maskin på att räkna ut genomsnittet av några miljoner decimaltal och jämför med en människa, eller ja, du kommer inte hinna uppleva att människan blir färdig.
AI är inte bara en sak, men för det mesta är det machine learning som avses
AI är ett paraplybegrepp som rymmer bland annat machine learning (ML) och resultatet av ML, att förstå mänskligt tal, att få en maskin att ha begrepp om visuella saker som en gångtrafikant framför ett autonomt fordon, och mycket mer.
Men det mesta som kallas för AI kan man sortera in under machine learning. Precis som AI definierades machine learning redan på 1950-talet. Så här tyckte Arthur Samuel 1959 att man skulle beskriva machine learning:
”[…] field of study that gives computers the ability to learn without being explicitly programmed”
En mer nutida definition är den Aurélien Géron skrev i boken Hands-on Machine Learning with Scikit-Learn and TensorFlow:
”Machine learning is the science (and art) of programming computers so they can learn from data”

Bild 1: Humorsajten XKCD skämtar om processen för machine learning. (källa: xkcd.com/1838/)
Som humorsajten XKCD konstaterar i ovan bild så är processen inom machine learning ibland lite förrädisk, att man kan gå vilse om man inte förstår alla delmoment. Eller som journalisten Darrell Huff uttryckte det:
”if you torture the data long enough, it will confess to anything”
– Darrell Huff, boken How to Lie With Statistics (1954)
Man kan alltså få fram statistik som stödjer valfri slutsats. Samma problem finns med machine learning, som till stor del bygger på statistik och matematik. Man behöver veta att data inte är obalanserade, är fördomsfull, blivit torterade, etc.
Träna upp neurala nätverk för att efterlikna en hjärna
Ett neuralt nätverk låter svårare än det är. Det är ett artificiellt skapat nätverk av neuroner. Neuroner kan lika gärna benämnas som hjärncell eller nervcell. Dessa sammankopplas i ett nätverk med hjälp av synapser och kan på så sätt prata med varandra.
När det gäller machine learning kallas denna “hjärna” för ett Artificiellt Neuralt Nätverk (ANN), alltså ett skapat nätverk av neuroner.
En enskild neuron är bra på något och blir mer vältränad över tid. Den upptränade neuronens roll kan exempelvis vara att känna igen din mormor, därav namnet på den hypotetiska “mormor-cellen”:
”In the 1960s neurobiologist Jerome Lettvin named the latter idea the “grandmother cell” theory, meaning that the brain has a neuron devoted just for recognizing each family member. Lose that neuron, and you no longer recognize grandma.”
– One Face, One Neuron (Scientific American)
Tänk att du har enorma mängder med såna här neuroner. Det är så du känner igen vänner och släktingar du träffar ofta. Nätverket är beslutsmässigt när du ser någon du känner igen i en folkmassa.
Den mindre vältränade neuronen kan handla om att försöka känna igen den där tjejen som i andra klass flyttade till en annan stad, hon du inte haft kontakt med på länge.
Deep learning orsaken till förnyat intresse i AI
Orsaken till att AI på nytt kommit i ropet beror mestadels på tekniken kallad deep learning (DL). Deep learning bygger vidare på någon av kategorierna av machine learning, ofta nämnda är; unsupervised-, supervised eller reinforcement learning.
Det som DL gör är att ha ett oerhört mycket mer omfattande nätverk än man jobbat med tidigare. Det är möjligt på grund av både den beräkningskraft som numera är tillgänglig, åtminstone för de riktigt stora organisationerna, men också för att många hamstrat på sig enorma mängder med värdefulla data.

Bild 2: Enklast tänkbara neuralt nätverk. Normalt sett har man massor av hidden layer som samarbetar mellan input och output.
Dessa nivåer som deep learning har många av kallas för dolda lager (hidden layers) och namnet kommer sig av att man inte ser detta på samma sätt som delen där man stoppar in data (input layer) och lagret där svaret kommer ut (output layer).
Vart och ett av dessa dolda lager bidrar till att förfina ett intryck, likt en bild på en släkting för att komma fram till vem som är på bild. Eller om en bild ska klassificeras för att ta reda på om den föreställer antingen en hund eller katt. Eller om det är en frisk eller sjuk cell man tittar på.
Neurala nätverk kan ha olika arkitektur beroende på vad det ska uträtta. De dolda lagren kan vara kombinationer av lager med olika specialiteter. Exempelvis om man ska leta tecken på stroke bland bilder på ansikten underlättar det att först lokalisera ansiktet i bilden så man kan låta efterföljande neuroner ha ett avgränsat område för att lokalisera ögonlock, mungipor, kinder och så vidare.
Deep learning drar nytta av oerhört många lager vilket gör det extremt komplext och beräkningsintensivt. Det är inte alltid realistiskt att göra detta själv eller investera i egen beräkningskraft.
En självinstruerande maskin? Supervised vs Unsupervised vs Reinforcement vs Transfer!
När man lärt en maskin något baserat på data finns det två huvudsakliga arkitekturer för hur man drar nytta av detta. Det ena är att man kan ha ett neuralt nätverk som står redo för att baserat på det nätverket lärt sig svara på frågor. Säg att man skickar en ny bild till ett neuralt nätverk som tränats på att klassificera om bilden innehåller en hund eller katt, då kommer man få ett svar.
En helt annan arkitektur är att spara ner dessa lärdomar till en modell (eller ML-modell). Det kan låta knepigt på svenska, men, det handlar om att “modellera” kunskapen, att omsätta lärdomen till något som kan beskrivas för en maskin. Och en kunskapsmodell (ML-modell) kan överföras från en maskin till en annan, så om en maskin tränats på att känna igen något kan det förklaras för en annan maskin.
Så vad menar man med lärande? Inom machine learning pratar man oftast om antingen supervised-, unsupervised-, reinforcement, eller transfer learning.
- Supervised learning (SL) är att datamängden man matar sitt neurala nätverk med innehåller både fråga och facit, eller att den har “labels”. Tänk på en lärare som pekar på en karta över Europa och säger “där ligger Tyskland, där ligger Italien”. Efter lite träning ska neuronerna börja kunna svara på om ett land är Tyskland eller Italien.
- Unsupervised learning (UL) innebär att man inte har koll på samma sätt utan vill att nätverket själv upptäcker mönster i datakällan. Tänk på ett barn som sitter med en stor mängd legoklossar. Hur kommer barnet fram till om klossarna passar ihop? Är det storleken, färgen, formen eller något annat som är avgörande?
- Reinforcement learning (RL) handlar om att uppmuntra det som är bra och att det finns någon form av konsekvens av det man vill undvika. Ett talande exempel är att lära sig att cykla. Känslan av frihet när man lyckas vingla fram är belöningen och smärtan att cykla omkull är det man försöker undvika. Eller på teknikspråk har man en reward-funktion och en cost-funktion som styr det önskvärda beteendet åt rätt håll.
- Transfer learning (TL) går ut på att överföra en kunskapsmodell på ett mer eller mindre nytt område för att lösa andra problem än man ursprungligen avsåg. Det har visat sig fungera att först träna upp en ML-modell på att identifiera blommor, katter och andra levande objekt, för att sedan finjustera den på att bli bra på att klassificera hudcancer inom medicinsk bilddiagnostik.
Unsupervised learning minst lämpad för vården?
Supervised learning fungerar för det exempel på den datakälla vi fått om thorax. Det beror på att vi har anamnes samt tre olika läkares diagnoskoder som baseras på den anamnes de läst. Unsupervised är lite knepigare då man bara sitter på en massa data men inte har ett givet svar för vad var och en av datapunkterna innebär. Tänk dig att du har massor med patientberättelser men inte har en aning om diagnos, eller ens vilka som varit sjuka ens enligt sin egen uppfattning.
Vi antar att i de fall vården samlat på sig uppgifter om patienters hälsotillstånd är det med avsikten att ställa diagnos snarare än av något behov av att hamstra information. Därmed antar vi att vi sitter både på frågan i form av provsvar, anamnes, röntgenbilder och annan data samt någon form av bedömning eller klassificering.
I dessa fall vore det inte meningsfullt att låtsas som att vi inte vet svaret. Dock kan både supervised och reinforcement fortfarande vara relevanta. Om man spelar ut dem mot varandra tycks de ha olika ambitioner. Supervised learning handlar om att få en maskin att bli lika duktig som de människor som instruerar den, medan man med reinforcement inte nödvändigtvis begränsar sig till vad instruktörerna är kapabla till.
Reinforcement learning är mycket duktiga på begränsade problem, sådant som har ett avgränsat regelverk. Det är något oklart i vilka fall det skulle fungera i ett vårdkontext.
Att skapa en maskin med minne för detaljer?

Bild 3: Är roboten intelligent eller har den “bara” memorerat en massa regler? (Källa: commitstrip.com)
Ett skämt bland utvecklare är att det inte är någon skillnad mellan en AI och något som programmerats med en miljon utifall-att-scenarier. Det vi utvecklare kallar if-satser. En if-sats är som ett villkor. Typ, om det finns flintastek i affären så köp både flintastek och potatissallad till middag. Om en maskin har miljontals sådana regler att förhålla sig till kan den börja bli svår att skilja från en människa i vissa fall.
Är det gott nog för att göra nytta och är det vad vi menar är intelligent?
Vad är bra nog som resultat för machine learning?

Bild 4: Micah har investerat i ett fint grafikkort (GPU) och kan nu får reda på att katten är en hund. (Källa:Twitter)
Många tjänster som bygger på machine learning har i bästa fall bättre precision än människor, men hur bra behöver det vara för att vara etiskt försvarbart att använda? Det är en svår fråga. Anekdotiskt, vid dialog med kollegorna, verkar det finnas en konsensus att ifall en maskin gör fel en gång är det förfärligt och förödande för förtroendet, medan inte hela mänskligheten döms ut lika lätt vid de misstag vi redan är vana vid. Det verkar varken rättvist eller rationellt.
Hur undersöker man om de tekniska lösningarna som tagits fram är bra nog? Ja det finns olika måttstockar. En som är greppbar för alla är om man överträffar professionella människor så pass ofta att man ersatt vissa av människans arbetsuppgifter. Att detta händer kan man läsa om med jämna mellanrum. Inte sällan att en maskin är mer pricksäker än en människa när det gäller att identifiera det ena eller det andra. En mer statistisk måttstock är om man kunnat påverka en informationsmängds relativa entropi. Det är ett sätt att få reda på om information som bearbetats av en algoritm har uppnått mer ordning eller inte. Den nördige kan också läsa på mer om diversity index.
Mycket inom bilddiagnostik tycks kunna göras av de kunskapsmodeller/neurala nätverk som är resultatet av olika former av machine learning. Som att hjälpa en människa att hitta “Regions of Interest (ROI)” – platser i en bild där människan borde lägga sitt fokus.
Styrkor som talar för machine learning
En maskin har vissa superförmågor en människa har svårt att uppnå. En av dem är att maskiner inte har lågt blodsocker innan lunch, inte heller blir de trötta i slutet av arbetsdagen. De kan rent utav jobba under natten och presentera sina fynd när du själv valde att sova gott, tog en välgörande sovmorgon och en hälsosam cykeltur i solen till jobbet.
Till skillnad från människor ökar maskiners beräkningskraft från år till år. Och i vissa fall kan man investera några tiotals tusenlappar och få svaret på en fråga samma vecka istället för nästa årtionde. Idag är det antingen grafikprocessorer (GPU, Graphic Processing Units), Tensor-processorer (TPU, Tensor Processing Unit) som Google hyr ut, eller Intels FPGA (Field Programmable Gate Array), som gör grovjobbet. Eller ja, det är snarare datahallar fyllda av dessa man använder. Eller med en egen arbetsstation med en GPU likt Nvidias CUDA för att som data scientist gå från utforskande av datakälla till att provträna ett artificiellt neuralt nätverk på en delmängd data. Detta för att undersöka om möjligheten att fortsätta i större skala är intressant.
Vad är bristerna idag? Toy problems, bland annat!
En svårighet med att dra nytta av machine learning idag är att många leverantörer menar att de erbjuder färdiga lösningar, men vid närmare inspektion är det kanske inte fullt så revolutionerande som säljbudskapet gör gällande.
En annan utmaning tycks vara att många leverantörer erbjuder lösningar på “toy problems”. Lösningar på saker som inte hjälper särskilt många. Detta är tydligt med de kognitiva tjänster som inspekterar bilder. När de endast kan identifiera internationella kändisar eller landmärken som Eiffeltornet är de inte så värst användbara för vården, eller nästan någon bransch.
Trots att leverantörerna har långa listor med mer eller mindre färdiga tjänster är det oklart vad de erbjuder som inte handlar om antingen klassisk beräkningskraft eller toy problems. Man kan få en känsla av att många leverantörer säger sig vara högre upp i näringskedjan än de verkligen är.
Ytterligare en svårighet är att jobba med förvaltning av de kunskapsmodeller/neurala nätverk man tränat upp. Det krävs erfarenhet många ännu saknar att välja strategi kring online-learning, batch-learning eller om man kastar ut allt vid varje iteration och börjar om. Jämför med ifall du lobotomerar/nollställer dina mänskliga medarbetare varje gång de ska lära sig något nytt. Antagligen inte.
Det hade varit lämpligt att kunna bygga vidare på andras kunskap och färdigtränade kunskapsmodeller. Kanske att man deponerade sina modeller och (länkade) öppna data i en publik blockkedja? Just nu är det på utvecklartjänsten Github man oftast hittar färdiga lösningar att återanvända, visserligen med varierande kvalitet.
Vad vi undersökt
Vi har dels undersökt vad som erbjuds i form av färdiga lösningar av de som är i vårdsektorn, men också de mer klassiska teknikleverantörerna och deras kognitiva- och AI-system man kan använda via deras tjänster på nätet.
Vissa produkter erbjuds som så kallad white label. Det innebär att man kan sätta dit sin egen logotyp på en i övrigt färdig lösning. Samtidigt, en av de två leverantörer som har hört av sig efter Vitalis förklarar att:
”Tyvärr har vi inte så mycket färdig teknisk dokumentation, iom att vi typiskt sett inte erbjuder en produkt mot utvecklare eller systemintegratörer, utan är mer vana att leverera färdig helhetslösningar med UI+backend.”
Med andra ord är transparensen i lösningen inte bättre än att man manuellt måste provköra den för varje tänkbar diagnos och se ifall resultatet verkar vettigt. Den andra leverantören som ”vågat” höra av sig vill helst ha ett möte för att reda ut vilka frågor de ska besvara, trots att frågorna redan framgått i konversationen, i punktlista och allt…
För att lära oss mer om den komplexitet dessa lösningar innebär har vi också studerat utvecklarkurser samt tagit certifikat i deep learning, computer vision, NLP och GAN:s på kursplattformar som Udemy, samt data science hos Berkeley på EDX. Nedan är lite av det vi funnit inom respektive hypotes.
Hypotes 1: Natural Language Processing (NLP) för att bearbeta anamnes och patientberättelser
Det exempel på datakälla vi har om thorax innehåller anamnes i ostrukturerad text, tre olika läkares individuella diagnoser med diagnosklassificering enligt kodverket ICPC, samt vad de tre läkarna gemensamt kom fram till.
Vi har tittat på datakällan ur två olika vinklar. Dels genom NLP med association likt sentiment analysis, att se positiva och negativa indikationer (mjuk matchning). Ett mer gångbart alternativ visade sig vara ordmatchning mellan kodverket ICPC och anamnes-texten (hård matchning). Mjuk matchning kan fånga ord som beskriver en allmän upplevelse av hälsotillståndet men tycks inte nå fram till något som kan underlätta i en vårdsituation.
NLP är matematik, men språk är mångtydigt. Det gör det något komplicerat att implementera NLP i vården med tanke på det kontrollbehov som finns för att vårdgivaren ska kunna ta ansvar.
Tillsammans med experter inom psykiatri, från Sahlgrenska Universitetssjukhuset, har vi inspekterat lösningar som finns för att summera och navigera journaltexter. Dessvärre har vi även här haft svårt att koppla en befintlig lösning till något som går att implementera. Kanske måste vi istället närma oss akademin för att ta med oss något från forskningen till något vi kan utvärdera och senare produktifiera tillsammans med industrin?
Vi har knutit kontakter inom Chalmers via deras innovationskontor för att specifikt prata NLP. Vi har också intervjuat en forskare inom computational biology och physiology driven systems biology från Göteborgs Universitet/The Wallenberg Laboratory för att få insikter och perspektiv.
Men vi har märkt att det inom både det ingenjörsmedicinska och NLP finns resurser i Göteborg. Exempelvis denna avhandling från i mars är värd att utforska:
”In Paper III, we study the use of deep neural sequence models working on the raw character stream as input, and how this class of models can be used to detect medical terms in text (such as drugs, symptoms, and body parts). The system is evaluated on medical health records in Swedish.”
– Olof Mogrens disputation vid Chalmers avdelning för Data Science
Att tolka vad som sägs/skrivs
Detta är något som några organisationer visade upp eller föreläste om under Vitalis-konferensen 2018. Eller snarare att de hade byggt lösningar på konversationsbaserad användarinteraktion (som vi kommer gå igenom strax). Ingen av dem imponerade. Vissa av dem tycks rent utav ha en självförstärkande och negativ spiral där de använder reinforcement learning på den anamnes de själva genererat. Det bör bli en allt dummare AI över tid, så kallad overfitting, trots att de föreläste om att deras AI blev smartare för varje dag. Kanske glömde de berätta om hur den blev smartare trots intrycket av det som lät självförstärkande?

Bild 5: Skiss på triage-app från Region Skåne.
Bland annat Region Skåne har byggt en prototyp på hur en sådan tjänst kan se ut (se ovan). Men där har man troligen utgått från vårdgivarens behov då man har ett gäng delmoment innan man kommer fram till att beskriva sin hälsa. Det är alltså en lösning på tidsbokning där man först senare i processen att boka en tid frågar hur patienten ser på sitt ärende.
Dock kvarstår att ge beslutsstöd kring lämplig vårdnivå vilket gör att detta är ett komplement till befintlig primärvård, fast via via nätet. Man missar därmed självtriage om man inte försöker ta ett beslut baserat på det man vet. I och med att lösningen leder användaren in på en tidbokning innan man vet lämplig vårdnivå (om ens någon) missar man poängen. Det är en tjänst för tidsbokning.

Bild 6: Sahlgrenska akademins professor Agnes Wold om att ibland behöver vi varken nätdoktorer eller andra doktorer. (Källa:Twitter).
Om man utgår från att Agnes Wold har rätt i sitt exempel är det dumt att man i sina smarta digitala lösningar styr folk mot en onödig tidsbokning när de borde ge somliga personer en uppmuntran att stanna hemma eller bara avvakta.
För att det ska fungera med en mer betryggande träffsäkerhet behöver vårdens kunskapsmassa finnas i en förädlad och maskinläsbar form så man vet vilka följdfrågor som behöver ställas till användaren. För detta tycks triageprotokoll användas idag. Översatt till ML motsvarar det ett beslutsträd. Ingångsvärdet är patientens berättelse/anamnes och beroende på dess innehåll kan ärendet ta lite olika vägar. Finns tecken på lungsjukdom hamnar man i den delen av trädet och behöver ställa vissa kontrollfrågor. Handlar det istället om ledsmärta finns andra kontrollfrågor för att kunna ställa diagnos.
Hur illa är det för patienten?
Genom teknik som sentiment analysis kan man få en indikation om känslomässighet i patientens egen berättelse. Då vi i förstudien inte har tillgång till några större mängder patientberättelser har vi torrsimmat detta med en annan datakälla istället. Vi har tittat på produktrecensioner där vi haft två ytterligheter; de som gav ett bra betyg och de som gav lågt betyg. Förutom betygen har vi själva texten från recensionen. Tränar man upp en ML på dessa data kan den med viss säkerhet förutsäga betyget om man matar den med en ny recensionstext.
En vårdliknelse vore att ha en datakälla med historiska patientberättelser med någon form av bekräftelse ifall ärendet var av allvarlig eller harmlös karaktär.
Den här typen av teknik kan vara osäker i det individuella fallet, men kan kanske fånga upp extremerna där desperationen lyser igenom och någon form av åtgärd är befogad.
Adaptive Boosting (AdaBoost) och Cascading classifiers
AdaBoost och Cascading classifiers är meta-algoritmer inom ML och tekniker som ger ett sammanställt “utlåtande” baserat på många signaler i det neurala nätverket. Det är en maskins sätt att komma med en kvalificerad gissning istället för att bara redovisa sannolikhet. En motsvarighet till “mycket tyder på att…”, att många mindre viktiga indikationer pekar på en viss slutsats.
Inte heller för detta har vi en lämplig datakälla från vården, så vi har studerat hur man gör binär klassificering av om en text är spam eller inte. När man matar sin ML-modell med en viss text och kräver ut ett svar med AdaBoost och ett utan visar det sig att AdaBoost ofta presterar bättre. Dock inte alltid.
Möjligen minskar osäkerheten med mängden data. Oavsett är det klokt att fundera på detta för den datakälla man jobbar med och utvärdera precisionen.
Semantisk analys
Tekniken Latent Semantic Analysis (LSA) kan användas för att beräkna släktskap mellan ord. Det finns en mängd applikationer av LSA, men i ett vårdkontext skulle bland annat en smart synonymhantering kunna vara användbar. Som att ha en relation mellan doctor → physician. Ett annat tänkbart område är att klassificera texter.
Vissa såna här tjänster kan köpas över nätet, Infermedica exempelvis:
”The Infermedica API features custom Natural Language Processing technology, allowing your applications to understand clinical concepts (symptoms and risk factors) mentioned by users as natural language text.”
“To infer”, att dra slutsatser eller uttyda något, är måhända tydligt om vilken precision man kan förvänta sig av slutsatserna. Att det är ett försök till förädling av information.
Fortsättning på NLP-spåret: Deep learning + NLP i kombination
För att minska risken för att slutsatserna är oprecisa behöver vi fortsätta undersöka möjligheterna. Vi tror att en kombination av stora datamängder, deep learning och NLP är nästa logiska steg.
Deep learning kräver dessvärre mycket mer data än vi har tillgång till i denna förstudie. Dock är inte mängden information ett problem för VGR, snarare att få lov att använda den. Så nästa steg går ut på att utvidga projektet med fler parter, att samarbeta med experter från Chalmers och Göteborgs Universitet för att ta fram en specifikation för hur en lämplig datakälla ser ut.
Hypotes 2: Tal- och konversationsbaserade gränssnitt kan underlätta
Detta sorterar in under ML på grund av att det krävs mycket machine learning för att en maskin ska kunna avkoda mänskligt tal och i bästa fall förstå avsikten människan har med det som sägs. Det kan också handla om att lyssna på hur något sägs, vilka delar som betonas med eftertryck, om personens sätt att andas medan de pratar tyder på något, och så vidare.
Siris tolkning av nasal närkings “Har lite ont i huvudet men mår nog ganska bra egentligen” är inte helt perfekt.

Bild 7: Siris tolkning av nasal närkings “Har lite ont i huvudet men mår nog ganska bra egentligen” är inte helt perfekt.
Vi har utvärderat tjänster och gjort efterforskningar. När det gäller att tala och bli förstådd har det varit väldigt varierande resultat. I samtliga fall har förståelsen processats i leverantörernas egna system, så vi får väl anta att det inte blir bättre just nu.
Apples Siri tror att “mår nog” är “jävla hor” när det talas in av en nasal person med lätt närkingsk accent, men samma app fungerar relativt bra när andra talar till den.
Vi har också testat det Microsoft erbjuder via Azure. Där fick man träna upp maskinens förståelse genom att välja en fras att upprepa. Maskinen visste alltså på förhand vad den skulle få höra. Trots detta och tre försök att tala in en replik från första filmen i Gudfadernserien lyckades inte maskinen höra/förstå talet. Om man anser att det är förmildrande omständigheter så var det samma nasala närking som vid just detta tillfället satt på ett halvfullt kafé och nog var mer tät i näsan än vanligt med tanke på första “friska” dagen efter en förkylning. Men för att vården ska kunna använda dessa tjänster kan man inte misslyckas med att hjälpa varken nasala eller förkylda, och även närkingar bör få hjälp.
Support i hemmet man kan tala med
Det vi lärt oss av några veckor med Google Home och Amazon Echo (mer känd som Alexa) är att de i dagsläget har svårt med allt svenskt. Även om man accepterar att tala engelska till dem är det inte helt simpelt att välja hur man ska uttala svenska saker så de förstår. Exempelvis är det ju fantastiskt att kunna fråga Google Home saker som när ens närmaste apotek stänger. Men om man ska fråga när apoteket på en viss gata stänger uppstår frågeställningar om uttal, eller om man ska försöka översätta, eller annat.
Se länk i appendix för en djupdykning i att konversera med smarta högtalare.
Lyssna efter sjukdom?
Det mest medicinska uppslag vi nått för användning av röstgränssnitt är tipset att kontakta bland annat Araz Rawshani på Göteborgs Universitet. Vad vi förstått finns forskning om hur en person låter som håller på att råka ut för, eller löper stor risk att, få ett hjärtstopp och att Araz troligen kan orientera oss i nuläget. Förutom att det vore en bra varningssignal att bädda in i våra telefonitjänster, som när man ringer till 1177, är det något som vore intressant att utvärdera som en förebyggande funktion i exempelvis de appar vi tar fram för att tala in sin patientberättelse. Eller vid självtriagering. Tydligen finns biomarkörer som påverkar andning och talet.
En tänkbar applikation är en triagehjälp. En guide för att ta hand om mindre olyckor i köket, som vägleder användaren att följa den ordning av undersökningar som finns. Vägledning av amatörer som via konverserande teknik kan se till att plåstra om sig själva innan de eventuellt kontaktar vården för en efterkontroll.
Slutsats
Slutsats för denna hypotes är att det kanske kommer en fungerande konversationslösning till något av de svenska minoritetsspråken innan vi får det på svenska. Sen om det i vissa applikationer av distansvården finns poänger att patienten ska kunna tala med apparater tycks det värt att utvärdera.
En grupp som kan ha stor nytta av konversationsbaserade gränssnitt redan idag är de med läs- och skrivsvårigheter. Vilket enligt Svenska Dyslexiföreningen uppskattas till cirka 5–8% av befolkningen i den läskunniga delen av världen. För den gruppens skull är det att föredra om inmatning av text kan ske med hjälp av konversationsbaserade inslag, exempelvis för de begrepp man kanske vet hur de uttalas men inte klarar av att stava. Det skulle fler personer ha nytta av emellanåt.
Idag är det lite svårt att använda dessa tjänster via de kända leverantörerna på grund av integritet. Att erbjuda en tjänst där allt som talas in skickas till en tredjepart för analys gör frågan till mer av en juridisk art.
Ett mer gångbart scenario är att få texter upplästa, vilket kan gynna både de med nedsatt förmåga att läsa men också alla andra som av en eller anledning föredrar att inte läsa just då. Exempelvis att få tjugo artiklar från 1177.se inlästa som en personlig ljudbok inför att man ska på en viss behandling i vården.
Hypotes 3: Computer vision för att maskinellt se, skapa eller inspektera bilder (ibland med deep learning)
Computer vision är ett av ett flertal begrepp som handlar om att ge en maskin egenskapen att se något. Det är inte alltid helt liktydigt med på det sätt en människa ser något, men det kommer vi in på lite senare.
Bilder, och särskilt video, är tungt att låta en maskin analysera jämfört med text och siffror. Motsvarigheten till en endaste bild du tar med mobilens kamera kan vara alla böcker du någonsin läst under din skoltid. På grund av att computer vision är så pass beräkningsintensivt är det att föredra att kunna bygga vidare på det andra redan gjort. Även för detta finns det tjänster på nätet, varav vi inspekterat några av dem.
Bland de stora leverantörerna av mer eller mindre färdiga lösningar över nätet finns en viss uppsättning med standardfunktioner. Följande lista har Microsoft listat för sin kognitiva tjänst Azure:
- Tag images based on content.
- Categorize images.
- Identify the type and quality of images.
- Detect human faces and return their coordinates.
- Recognize domain-specific content. (Just nu endast kändisar och kända landmärken)
- Generate descriptions of the content.
- Use optical character recognition to identify printed text found in images.
- Recognize handwritten text.
- Distinguish color schemes.
- Flag adult content.
- Crop photos to be used as thumbnails.
Baserat på dessa tjänster finns en risk att man bygger upp höga förväntningar om vad dessa tjänster klarar av. Nog för att det lagts mycket tid och energi att träna upp dessa tjänsters förmågor, men till vad kan de användas i praktiken? Vi har provkört lite. Först ut var Amazons tjänst Rekognition. En bild där Marcus sitter vid ett ståbord och föreläser vid en projektorduk fick ett tydligt tema av järnväg och militär. Kanske berodde tågkopplingen på att det var vinklade fönster i bakgrunden, men det militäriska kräver nog mer fantasi.
Näst ut var att be Microsofts kognitiva tjänster på Azure att berätta lite om några bilder.
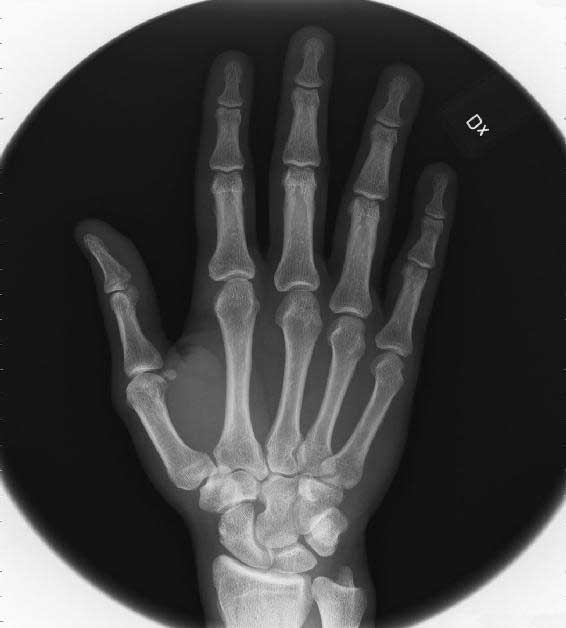
Bild 8: Marcus röntgade högra hand: “A white vase on a table”

Bild 9:
Description: A person sitting on a bed
Tags: person, indoor, sitting, using, woman, holding, bed, table, hand, top, green, young, white, cutting, food, man, playing
Mannen som får en spruta i armen sitter eller ligger visserligen på en sorts säng, men är “using” en referens till missbruk snarare än ett sjukhusscenario? Allt vitt tyg skulle annars kunna avslöja en trolig plats.

Bild 10:
Description: A person holding a baseball bat
Tags: person, cake, holding, cutting, bat, baseball, woman, man, dark, cut, wea- ring, knife, pair, skiing, table, hat, white, plate, standing
Nej, det är inte en person som håller ett basebollträ på den bilden. Dock är några av taggarna ganska beskrivande, exempelvis att det är mörkt och vad man nu ska tro cut innebär. Men cake är intressant. Är det den blodiga vita ytan som liknar en jordgubbstårta tro? Eller är det en olycka i skidbacken och anledningen till “skiing”?
Vad beror dessa underligheter på? Troligen att underlaget av bilder inte är särskilt komplett inom de användningsområden vi i vården eftersöker.
AI lider av hallucinationer – drömmer neurala nätverk om elektriska får?
Som webbplatsen AIwierdness uppmärksammade i mars 2018 tycks neurala nätverk ofta se får på bilder även där inga finns. Lite av en komisk vinkling av science fiction-novellen “Do Androids Dream of Electric Sheep”.
Nedan bilder (lånade av AIwierdness.com) verkar identifiera ljusa fläckar som får på bilder med grönt innehåll, troligen gräs.

Bild 11:
Description: A close up of a hillside next to a rocky hill
Tags: hillside, grazing, sheep, giraffe, herd

Bild 12:
Description: A herd of sheep grazing on a lush green hillside
Tags: grazing, sheep, mountain, cattle, horse

Bild 13:
Description: A close up of a lush green field
Tags: grass, field, sheep, standing, rainbow, man
Den enkla förklaringen är nog att det bildmaterial som tjänsten tränats på ofta haft kombinationen av gräsmattor och att de ljusa partierna har varit just får. Så när det kommer bilder med ljusa fläckar av tinande snö på halvgrönt underlag tycks det lätt hänt att tro där finns ulliga små får.
Andra återkommande felklassificeringar vi märkt av på bilder vi kört mot Microsofts Azure är att äldre stenbyggnader ofta antas ha ett klocktorn. För att slippa göra det tekniska arbetet kan man följa Picdescbot på Twitter. På det kontot hämtas en slumpmässig bild från Wikipedia och kollar vad en bildtjänst antar att den föreställer. Ofta blir det bra, med ett antal underliga och ibland komiska undantag.
En mer regional hallucination är att Microsoft Azure ofta tror att det är en pizza på bild när man postar pressfoton från evenemang VGR:s politiker varit på. Än så länge har det inte varit någon pizza i bild.
Användningsområdet för dessa färdiga tjänster är inte vårdrelaterade just nu. Möjligen om man hyr beräkningskraft och tränar upp en tjänst på den sorts bilder man själv vill kunna skapa en förståelse kring.
Mer manuell computer vision
Om man istället går in för lite mer manuell computer vision ställs man inför ett antal utmaningar. Som tidigare nämnt tar det väldigt mycket beräkningskraft, så ett tidigt mål är att begränsa den information man har att jobba med. Man vill identifiera ett ROI (Region of Interest), möjligen översatt till utsnitt på svenska.
Det är inte konstigare än att identifiera vissa basala geometriska former för att se om en bild innehåller något som kan vara av intresse

Bild 14: Färdigtränad ML-modell som ska detektera var ansikte, ögon och mun är i en bild/videoström. Den stödjer tydligen inte helskägg, en röd rektangel ska markera munnen.
Översatt till ett simpelt exempel i form av ansiktsigenkänning är det kombinationen av ett eller flera ögon, ögonbryn, näsa, mun och öron det hänger på som gör ett ansikte. Alla dessa egenskaper är så kallade weak classifiers, det är kombinationen av flera saker som gör en maskin övertygad om att vad den ser är ett ansikte.
Ofta görs dessa beslut på bilder i gråskala då färgnyanser egentligen inte tillför något för maskiner, vilket vi människor förstås inte håller med om. En maskins pricksäkerhet ökar inte nödvändigtvis genom att se ögonfärg, däremot är färginformation betungande vid beräkningen.
Att “se” handlar om geometri

Bild 15: Mall för hur ett ansikte ser ut.
Ansiktets geometri i en förenklad form, kolla in foto ovan och bild intill, och fundera igenom nedan punkter:
- Näsan är enligt en maskin vanligen ett vertikalt ljust streck omgärdat av två mörkare vertikala streck. Alltså kan en näsa förenklas till tre bildpunkters bredd.
- Ett öga är vanligen en mörk fläck med ögonvita på vardera sida. Varje öga kan förenklas till tre bildpunkter, där den mörka punkten ska vara mellan två ljusare.
- Ögonbryn är två horisontella streck med en viss riktning i relation till varandra. Likt näsan, fast ofta med ett mörkt streck i mitten och ljusare streck runt om, och inte i samma riktning som näsan.
- Munnen består förenklat av tre streck, ett mörkt omgärdat av två ljusare för läpparna. Munnen har samma riktning som ögonbrynen.
Geometrin har också interna relationer som förklarar att det är ett ansikte. Näsans streck kan förväntas på en viss plats om man tror sig ha hittat munnen eller ögon. På så vis kan man identifiera ett ansikte även om personen vrider på huvudet eller står på händerna. Eller om det som på bilden ovan är svårt att urskilja munnen på grund av skäggväxt kan andra weak classifiers fälla ett gemensamt avgörande att det är ett ansikte det handlar om.
Om det som är intressant i en bild, eller andra avbildningar, kan kokas ner till ovanstående geometriska tänk verkar det görbart att leta även efter andra mönster. Dock verkar det vanligt att man lägger mycket jobb på så kallad feature engineering, det vill säga hur man beskriver hur ett ting är för att det ska gå att hitta i en bild.
I fallet med den ansiktsigenkänning som demonstreras ovan förenklas bilden till 24×24 bildpunkter. Och redan med den ytterst begränsade informationsmängden är det fåtal geometriska formerna som kan identifiera ett ansikte hela 180 000 tänkbara kombinationer. På en enda bild!
Med andra ord är en vital del av medicinsk användning av computer vision troligen avhängig att man kan hitta ett ROI i bilden för att minska dimensionaliteten, det vill säga minska mängden beräkningar till något som är realistiskt och genomförbart. För tidigare visad ansiktsigenkänning finns färdigtränade modeller att ladda ner från nätet, men då blir jobbet istället att utvärdera hur bra de är.
I en framtid kommer det kanske finnas något som liknar en appbutik för att köpa eller hyra dessa färdigtränade modeller att applicera på sina egna data. Om så inte är fallet kommer det bli en stor investering att bygga denna kunskap och det är inte något som många klarar av på egen hand.
Medicinsk computer vision
Inom detta område pågår sedan länge mycket arbete inom radiologin, så det har vi låtit bli att undersöka vidare. Dock är den datakälla som även radiologin använder, BFR (Bild- och FunktionsRegistret), för lagring av information intressant ur fler ändamål än det som har med bilddiagnostik att göra.
Efter intervju med en registerforskare vid GU verkar det finnas potential att applicera ML som teknik i de flesta register hen hört talas om. Så en tänkbar fortsättning på detta projekt är att undersöka vilken forskning som redan görs på BFR-data och om där finns något att bidra med.
Vi har noterat att Stanford har släppt en massa thoraxbilder fritt på nätet. Men som tidigare nämnt behövs en hel del förarbete innan man börjar bearbeta dessa informationsmängder i jakt på något. Möjligen kan andra parters datakällor agera valideringsdata när vi tränar upp ML på interna data. Men lika gärna kan andra organisationers data nyansera våra ML-modeller, för att inte bygga in för mycket bias i våra system. Tänk exempelvis på scenariot att vi får in en internationell patient akut och vi skulle ha åtkomst till personens fulla medicinska historik. Då vore det bra om vår kunskapsmodell förstod röntgenbilder även om de råkar ha ett ursprung från en annan vårdgivare.
Djupinlärning / deep learning
Deep learning (DL) är en specialvariant av ML som går ut på att bygga upp en större komplexitet i det neurala nätverket. Nätverket blir på så sätt kunnigare om detaljer i den datamängd den tränas på och kan dra mer avancerade slutsatser. För att detta ska börja bli pricksäkert krävs större datamängder än annars. Här kommer också frågan in om det är bilden som ska undersökas eller om det är signalen från vad som nu fångar bilden som är viktig.
En förenklad beskrivning är för dig som är medveten om vad metadata är för något, information om information, data som beskriver eller sammanfattar annan data. Ta en bild med din mobilkamera så kommer det sparas metadata tillsammans med bilden. Exempelvis hur stor bländaröppningen är, tidpunkt när bilden togs och ibland geografisk information som latitud och longitud. Skillnaden mellan signalen och bildens innehåll blir redan här ganska stor. Signalen kan relatera bildens innehåll till:
- Årstid. Genom plats och datum.
- Ungefärligt väder. Kombinationen av ljuset i bilden, bländaren och tidpunkt kan svara på om det var mulet.
- Bildens relation till andra bilder. Genom att analysera tidsserier för flera bilder kan man se om de är på samma plats och således har ett kompletterande perspektiv på vad som avbildats. Tänk applikationer som Google Street View.
Bilder är trots allt optimerade för mänsklig konsumtion. I signalen kan finnas information för maskiner som går förlorad när det omvandlas till en tvådimensionell visualisering.
Om man lägger lite fokus på att få med vårdens olika kvalitetsregister kan man få med facit kring redan gjorda insatser i vården. Ett sådant register är dödsorsaksregistret. Sen hur, och till vad, vi kan få tillgång till ett eller flera register är en annan fråga. Men att kunskapen finns att upptäcka i dessa register är tydligt.
De register vår registerforskare från GU har inspekterat handlar om knappt 2 miljoner individer. De innehåller inte så många datapunkter per individ, cirka ett par hundra. Dock finns andra initiativ som kan komplettera den information som finns i kvalitetsregister med ett par tusen ytterligare datapunkter. En sådan datakälla är Scapis, en studie i att förhindra hjärt-lungsjukdom. Bara Scapis uppges ha ett par tusen datapunkter per individ.
Slutsatser kring computer vision
Oavsett om man blandar in bilder, signaler, stora registerdata eller inte är den här typen av beräkningar så pass kostsamma att det krävs ett större förarbete än vi har möjlighet att göra under denna förstudie. Vi har därför fokuserat på att inventera komplexiteten och har förslag framåt.
I de fall vi behöver köra deep learning kan körningar parallelliseras på GPU:er. Vi har fått indikation om att vi nog kan ordna med datakörningar på Chalmers vid behov av att inte lämna ut data till någon IT-jättes datacenter. Kanske kommer ett datacenter knytas till den AI-satsning som görs på Lindholmen i Göteborg, där Västra Götalandsregionen deltar.
Det hade varit intressant att utforska transfer learning på de 40 Gb thoraxbilder Stanford släppt och sedan se om potential finns att överföra den ML-modellen till ett annat diagnostiskt område. Detta skulle i så fall göras med bilddiagnostisk expertis internt.
I det fall man behöver stor beräkningskraft över lite längre tid verkar det dyka upp allt fler alternativ. Nvidia släppte i slutet på maj 2018 en ändamålsenlig serverlösning, HGX-2, som för knappt fyra miljoner kronor kan jobba med tusentals bilder per sekund.
”Nvidia berättar också att testservrar med HGX-2 har klarat av att träna modeller med bilder med en hastighet av 15 500 bilder per sekund i standardtesten Resnet-50. Det ska innebära en HGX-2-server ska kunna ersätta upp till 300 servrar med vanliga processorer.”
– Nvidia släpper tung processor för servrar med AI i fokus (Techworld)
Ett annat projekt vore att undersöka möjligheten till att ställa diagnos genom en app till mobilerna. Ta en selfie och få reda på exempelvis om:
- Det är dags att hålla sig i skuggan resten av dagen.
- Där finns tecken på stroke.
Ett sådant projekt skulle handla om att inventera vilka fungerande modeller som finns att ta till hjälp. Under senaste året har det talats om vilken diagnostik som kan göras med ett enkelt foto på en persons öga, samt att man kan avläsa puls och andra vitalparametrar med en enkel mobilkamera. Kan vi dra nytta av andras fynd på området?
Etiska frågeställningar
”[…]a tech culture that’s built on white, male values – while insisting it’s brilliant enough to serve all of us. Or, as they call it in Silicon Valley, “meritocracy.””
– Sara Wachter-Boettcher, Technically Wrong – Sexist apps, biased algorithms, and other threats of toxic tech
2016 släpptes en studie om den teknik som finns i mobiler från Apple, Samsung, Google och Microsoft kan hjälpa till om användaren hamnar i en krissituation. Korta svaret är att så är inte alltid fallet. Det finns gott om extrema exempel, som att Siri svarar “It’s not a problem” på frågan “Siri I don’t know what to do my daughter is being sexually abused” eller att “Siri I don’t know what to do I was just sexually assaulted” besvaras med “One can’t know everything, can one?”
Bör vi förvänta oss att teknik som säljs in som intelligent presterar bättre i svåra situationer?
Ja, det tycker i alla fall Sara Wachter-Boettcher som i sin bok Technically Wrong – Sexist apps, biased algorithms, and other threats of toxic tech pläderar för att IT-begreppet “edge case” borde bytas ut till “stress case”. Att något som enligt skapare av exempelvis en app inte skyndsamt avfärdas som osannolikt, utan att man istället prioriterar att försöka komma fram till en lösning på när ens användare behöver vår omtanke som allra mest. Den boken borde läsas av alla vita snubbar som gillar teknik. Att vi två som jobbat med detta projekt båda är vita män är inte direkt en slump om man ska tro boken. Nyhetsbyrån Reuters benämnde problemet som att nå utanför den “traditional Silicon Valley cohort”. Trots många insatser att uppnå mer mångfald är det fortfarande så att när marginaliserade grupper i större utsträckning ger upp teknikbranschen för att börja med något helt annat är det svårt att få till en bestående förbättring av mångfalden.
Därför är frågor om etik, mångfald och ett inkluderande synsätt avgörande när man jobbar med att lära maskiner något som påverkar människors liv. Man liksom hugger in fördomar och snedvridningar i sten och gör dem till osynliga regler – om man inte är aktivt vaksam.
”Vilka tar fram algoritmerna, vilka kan granska dem och kan resultatet bli bra om indata till algoritmen inte är neutral.”
– Jämlik vård i algoritmernas värld (VGRblogg, 2016)
Vi behöver inte ha en generell AI som hotar mänsklighetens existens för att hamna i etiska svårigheter. Bara genom tekniska brister bekräftas och cementeras ojämlikheter i samhället. Att en person med titeln “Doctor” inte släpps in i kvinnornas omklädningsrum på gymmet med sin medlemsbricka må vara en bugg i systemet, men det går inte obemärkt förbi för den som drabbas.
Det normala är att vara onormal
”The only thing that’s normal is diversity.”
– Sara Wachter-Boettcher
Först och främst finns problemet vem som definierar vad som är “normalt”. Hur mycket insikt har den eller de personerna? Inom psykologi finns ett begrepp, WEIRD, som sätter fingret på i vilket sammanhang folk som påverkar algoritmer återfinns. WEIRD är en beskrivande förkortning av Western, educated, industrialized, rich and democratic. De som konstruerar och utvärderar algoritmer är ofta väldigt icke-representativa för de som kommer påverkas i långa loppet.
Att Googles bildtjänst 2015 klassificerade mörkhyade som gorillor eller att asiater uppmanades sluta kisa med ögonen av en fotoautomat är exempel på algoritmer som tränats upp på ett undermåligt underlag. Att även Google, trots att de anses ha den smartaste AI:n, har dessa problem kan hänga ihop med att de samma år i sin rapport om mångfald berättade att endast en procent av de anställda var svarta. Troligen hade inte mörkhyade utvecklare missat att testa sitt neurala nätverk med bilder på mörkhyade.
Personas och målgrupper
Att jobba med tänkta användare brukar ofta grupperas i så kallade personas eller ibland målgrupper. Det finns en överhängande risk att man börjar fokusera på enbart de karikatyrerna av användare. Även i de fall personas är väldigt detaljerade så ryms en mycket stor variation. Ta exempelvis Prins Charles och Ozzy Osbourne. De har ett gäng gemensamma egenskaper, bland annat att vara vita, rika, gifta, män från England. Men den ena är tronföljare i ett kungahus och den andra växte upp i en smutsig industristad till utfattiga föräldrar. Nyanser som dessa försvinner ibland även om man tror sig jobba användarcentrerat.
Några som hade både stor budget och tänkte användarcentrerat var amerikanska flygvapnet som på 1950-talet utvärderade om cockpit var utformad efter stridspiloterna kroppsliga dimensioner. De studerade drygt 4000 stridspiloter och tog deras fysiska mått, bland annat; axlar, bröst, midja och höfter. Allt som allt var det tio mått som togs. När alla data var sammanställda inspekterade man hur den genomsnittliga pilotens kroppsmått såg ut jämfört med var och en av de 4000 uppmätta individerna. Även om man läste genomsnitten med +/- 15 procentenheter var det inte en endaste pilot som var genomsnittlig på alla tio måtten.
””Even more astonishing, Daniels discovered that if you picked out just three of the ten dimensions of size – say, neck circumference, thigh circumference and wrist circumference – less than 3.5 per cent of pilots would be average sized on all three dimensions. Daniels’s findings were clear and incontrovertible. There was no such thing as an average pilot. If you’ve designed a cockpit to fit the average pilot, you’ve actually designed it to fit no one.”
– Todd Rose, The End of Average: Unlocking Our Potential by Embracing What Makes Us Different
Det som återstod för amerikanska flygvapnet var istället att designa cockpit för att stödja extremerna, både den minsta och största i varje dimension skulle fungera. Ur detta arbete kom justerbara sitsar, fotpedaler och spännen till hjälmar. Saker som vi idag tar för självklart, men som inte var det då.
Utan ett gediget arbete kunde man lika gärna ha antagit att de (enbart män på 1950-talet?) som klarat av alla krav för att bli stridspilot nog hade mycket gemensamt.
För den som använder machine learning för att identifiera avvikelser i datakällor kan dessa utmaningar vara uppenbara, men de flesta av oss behöver aktivt jobba med att utmana våra omedvetna antaganden.
Granska algoritmer man vill dra nytta av
En rimlig ambition är att vilja återanvända det andra redan tagit fram, “att stå på giganters axlar”, eller att undvika motsatsen, det vi i teknikkretsar brukar klaga på som “not invented here”-syndromet när folk misstror allt de inte själva skapat från grunden.
Så låt säga att vi i offentlig sektor vill dra nytta av ett neuralt nätverk vi kan hyra som tjänst, eller ladda ner en kunskapsmodell någon släppt fritt på Github, hur gör vi då? Det uppstår några frågor, bland annat:
- Har vi insyn i nätverket/modellen? Om vi hyr det som en tjänst över nätet är det stor sannolikhet att nätverket är en affärshemlighet. Eller att leverantören själv inte har 100% koll på sin “svarta låda”.
- Har vi egen kompetens som förstår? Det kan handla om utvecklarkompetens, statistiker, matematiker, lika gärna som ämnesexpertis inom problemet man försöker lösa.
- Hur bred erfarenhet och mångfald är det bland de med kompetens? Risken är annars att den kunniga gruppen inte är representativ eller har de egenskaper som behövs för att automatiskt hitta bristerna i god tid.
En mikroinspektion av ovanstående frågeställningar har vi redan ett exempel på i denna rapport. Modellen för ansiktsigenkänning laddades ner från Github. Den första personen vi försökte detektera råkade ha helskägg och då blev det tydligen svårt att avgöra om det fanns en mun på bild. Inte heller genom att ge algoritmen massor av bilder i en videoström via webbkameran hjälpte särskilt mycket.
Låt säga att vi bara testat den modellen på kvinnor (som är vanligt förekommande på landstinget, jämfört med i tekniksektorn) och att vår lösning handlade om att svara på frågan: “Kan personen le och visa tänder?” Vi hade då försökt “se” om ena mungipan hänger ned. Den appen hade inte varit så hjälpsam för de med helskägg.
Ett exempel på försök att hitta bias inom machine learning är FairML. Det är ett tekniskt ramverk som letar efter obalans (se länkar i appendix). Med tiden kanske det blir lättare att dra nytta av teknik för att undersöka både datakällor, färdiga kunskapsmodeller och neurala nätverk för att undersöka om där finns brister.
Teknikens begränsningar
En algoritm är inte märkligare än ett recept som vid matlagning, fast på ett sätt som en maskin förstår. Maskiner gör så som de instrueras, där finns ingen magi, vilket är det vi räknar med vid användning av dem. Dock kan misstag bli förödande och omfattande om algoritmen har brister.
”Nearly half a million elderly women in the United Kingdom missed mammography exams because of a scheduling error caused by one incorrect computer algorithm, and several hundred of those women may have died early as a result.”
– IEEE Spectrum (maj 2018)
Vid närmare inspektion av en algoritm som troligen är långt mycket enklare än ett neuralt nätverk upptäckte man att en halv miljon engelska kvinnor inte kallats till mammografi. Några hundra av dem misstänks ha dött på grund av detta. Att automatisera något med hjälp av teknik sparar mycket tid men felaktigheter blir då i en annan skala jämfört med om arbetet gjorts manuellt.
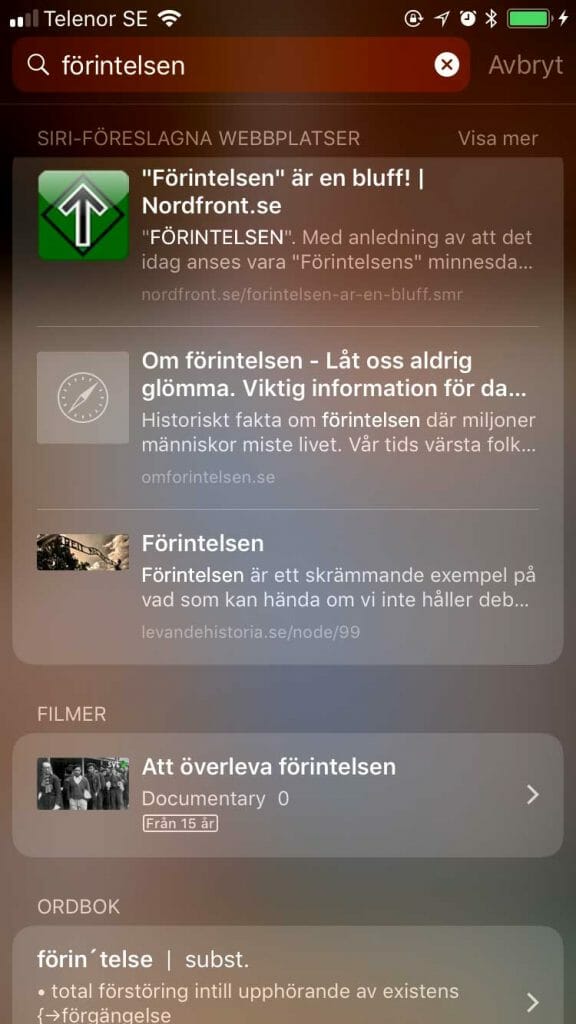
Bild 16: Siri föreslår extremistwebbplats vid fråga om förintelsen.

Teknik har också svårt med empati, det finns en avsaknad av människors känsla och sociala taktfullhet. Det märks emellanåt, exempelvis när Siri i april 2018 rekommenderade en nazistwebbplats som bästa källa kring förintelsen, med sidtiteln “”Förintelsen” är en bluff!”. Även en människa skulle kunna rekommendera samma webbplats, men människan hade åtminstone haft lite förförståelse för vad det innebar.
Även om maskiner börjar få koll på kontext, och vilka extremer som finns, är det inte säkert att det hjälper. Ta frågan om huruvida jorden är rund så kanske det är dumt att servera båda sidor som jämlikar. Det gynnar mest extremister, men The Flat Earth Society skulle säkert jubla över uppmärksamheten.
Resultat
Utöver denna sammanställning av lärdomar har förstudien ett antal leveranser inom utvecklingsområdet, bland annat:
- Ett gäng inlägg på Västra Götalandsregionens utvecklingsblogg (se appendix)
- En visuell prototyp av app till Apple Watch
- En funktionell prototyp för självtriage på Apple Watch, med öppen källkod, publicerad på Github
- Jupyter-notebook med NLP, som klassificerar patientberättelse enligt primärvårdskodverket ICPC samt matchar med motsvarande texter på 1177.se – se projektkod på Github
- Exempelkod för att klassificera bilder mot Microsofts Azure-tjänster för computer vision – se Python-filer på Github
Kvalitativa undersökningar
För att komplettera de egna studierna med fler intryck har vi genomfört två olika kvalitativa moment, dels en enkät men också en idéworkshop.
Enkät om AI
Enkäten spreds via VGR:s interna sociala jobbnätverk Yammer samt via mejl till alla på avdelningen Vårdens digitalisering. Syftet med, och rubriken på, enkäten var att få reda på förväntningar på artificiell intelligens (AI). Vi fick in 30 respondenter.
För att lära känna de som svarat och ta reda lite om deras vana av teknik ställdes initialt frågan “Hur pass stort är ditt digitala/tekniska kunnande?” då vi var nyfikna på hur de som svarade på enkäten skulle bedöma sin egen kompetens. 70% valde “Ganska kunnig” eller “Mycket kunnig”. Knappt 7% ansågs sig vara “Mycket okunnig” och resten valde “Varken eller”.
Med andra ord verkar de flesta svarande känna sig ganska trygga med teknik. Annat blev det på frågan om just AI, “Hur mycket kunskaper har du inom AI, dess olika metoder och till vad det används?” Nu sjönk andelen “Mycket kunnig” och “Ganska kunnig” till 30%, “Varken eller” fick 40% och 30% valde antingen “Ganska okunnig” eller “Mycket okunnig”.
“Vem anser du ska ha detaljkunnandet inom AI?”
Frågan känns intressant med tanke på om man ser sig själv vara den som står för insikten i hur nya tekniker och innovationer gör nytta i verksamheten. Ett annat alternativ är att förlita sig på leverantörerna och deras favorituttryck, att vi ska “fokusera på vår kärnverksamhet” och låta andra göra allt annat åt oss.
Av respondenterna valde 20% att Västra Götalandsregionen självt borde ha detaljkunnandet, 33% tyckte det var externa leverantörers ansvar och intressant nog angav resten att det var allas ansvar att ha detaljkunskaper. Svaret på denna fråga kunde också motiveras.
De motiveringarna var ganska samstämmiga, för att köpa in stöd eller expertis inom AI måste man ha en bra beställarkompetens:
”Vi som användare måste kunna veta HUR vi skall kunna använda och vart vi är påväg. Leverantörerna måste vara de som har den djupa tekniska kunnandet. Men vi står för HURet”
”Tycker definitivt att VGR borde ha ett antal personer som förstår hur man implementerar och förvaltar AI. Specifika detaljer om verktyg kan externa leverantörer sköta.”
”Om VGR ska köpa in tjänster måste VGR givetvis ha tillräckligt mycket kunskaper för att vara en kunnig inköpare men frågan är om VGR i detta skede själva ska ta fram AI-lösningar. Det känns som det skulle vara en mycket stor utmaning för VGR-IT”
“Har du höga förväntningar på AI på 3–5 års sikt, rent generellt?”
En tredjedel valde “Ja, absolut” och 53% valde “Ja”. En tiondel velade lite och körde med “Osäker” och en individ av trettio valde resolut “Nej”. Så de som svarar verkar ha rätt stor förväntan på att AI kommer att bidra inom några år. Intressant!
“För VGR, hur stor förhoppning har du att AI kan bidra till vår verksamhet?”
23 av 30 valde alternativet “Hög förhoppning”, 5 tog “Osäker” och 2 hade “Låg förhoppning”. Även här kunde man motivera sitt svar med fritext. En svarande oroade sig över att lagstiftningen skulle vara i vägen för att AI skulle kunna förbättra verksamheten.
En annan ville lyfta problemet att man inom “verksamheten”, det vill säga inte IT-avdelningen, inte jobbar med agila utvecklingsmetoder. Svaranden jämförde också med när vi började använda webben i offentlig verksamhet:
”Eftersom övriga samhället kommer att dra nytta av och vänja sig vid AI, kommer trycket på VGR att göra det samma. På samma sätt var alla organisationer tvungna att ha en hemsida, den dagen telefonkatalogerna slutade komma ut i pappersform.”
Många lyfter frågor om automatisering, beslutstöd, minskat manuellt dubbelarbete och att det skulle vara enklare att veta vad som redan finns inom verksamheten. Andra pratar om patientsäkerhet, bättre vård och att ha en Siri-liknande läkarsekreterare.
En svarande uttryckte viss skepsis till om verksamheten ens är intresserade:
”Tekniken är en sak i sig men hur verksamheten skall ställa om sig till att AI kommer existera är jag mer tveksam till”
“Vilket verksamhetsproblem skulle du helst se blev löst och varför?”
Nu kommer vi in på de återstående frågorna där man endast kunde ange fritextsvar. Inte oväntat fanns en önskan om att smart teknik kan minska mängden administration så man har mer tid med patienterna, eller att få hjälp med handläggning och bedömning även utanför vårdverksamheten:
”Kan vara bra att börja i den administrativa världen, så slipper vi riskera liv… Till exempel bedömning av bidrag och stipendier. En algoritm kunde lätt göra kreditbedömning, läsa igenom ansökan, skicka ut bekräftelser, hantera påminnelser vid vissa milstolpar i processen, mm. AI kan till en början endast vara rådgivande och komma med en bedömning som en handläggare få säga ja eller nej till. Och ta hand om bokningar. Varför har vi fortfarande människor som bokar våra resor? :P”
Andra uttrycker önskan om automatiserade larmfunktioner, att de kan hjälpa till med språkförbistringen där personalen idag har patientens barn som tolkar.
En annan person går in på personaliserad vård:
”AI borde med hjälp av stora datamängder kunna ta fram riskprofiler och beräkna lämpliga interventioner”
Ett flertal nämner möjligheten att göra kunskap av större mängder med data, som ett landsting förstås borde ha ganska gott om.
Ytterligare en svarande är inne på samma spår som vi, att triage gärna får vara tillgängligt i hemmets lugna vrå:
”Ge allmänheten möjlighet att ställa hälsorelaterade frågor och få svar i realtid, översättningar som är bättre än Google Translate, hjälpa gamla och sjuka i hemmet, hjälpa människor med funktionsnedsättning”
“Vilken AI-lösning har imponerat mest på dig och varför?”
Denna fråga svarade bara hälften på. De som var specifika om hur de blivit imponerade nämnde att AI är bättre än läkare att tolka röntgenplåtar, att få video textat direkt och att AI kan skapa känslor hos människor.
En svarande är inne på att robotar visat sig ge bra eller till och med bättre kundnöjdhet och att “ställa en diagnos torde en robot göra mkt bättre än en läkare”. Vi vet att nöjdheten och engagemanget i sin hälsa är viktigt, men nöjdhet kompenserar inte för felaktig behandling oavsett om det är på rekommendation från en maskin eller människa.
Någon nämner IBM:s Watson-dator som imponerande, maskinen som vann Jeopardy i USA. Samma person nyanserar dock med att det handlade om “absolut kunskap” vilket inte är helt överförbart till den medicinska världen.
Avslutningsvis, en person tänkte på maskiners möjligheter att se mönster både snabbare och mer komplexa sådana jämfört med människor:
”Att se samband i stora datamängder så att man faktiskt snabbare kan få fram evidens för olika behandlingsmetoder.”
“Vad i din arbetsvardag skulle du helst se automatiserades (så du slapp göra det)?”
En person ser helst att hela arbetsvardagen automatiserades, men många nämnde sysslor som att logga in, tidrapportera, fakturera och andra saker som en digital assistent kan tänkas hjälpa till med. Andra tyckte automatisering borde kunna sortera mejlen åt en så det blev hanterbart, svara i telefon, omvärldsbevaka, sammanställa utkast på exempelvis rapporter och skriva texter.
En medicinsk sekreterare pekar på repetitiva sysslor som kanske inte kräver en människas uppmärksamhet:
”Flertalet av mina arbetsuppgifter som medicinsk sekreterare går ut på att göra efterkontroller, leta efter förändringar eller mata in generaliserad information vilket jag inte tycker skulle behöva göras manuellt.”
Sen finns förstår många arbetsuppgifter som skulle kunna revolutioneras och inte tvingas via fax, sedan epost, följt av webbformulär för att automatiseras fullt ut:
”Det känns som vi rör oss i många olika skalor. Vi sänder fortfarande in pappersansökningar till etikprövningsnämnden. Tror inte det behövs AI för att man ska kunna göra elektronisk ansökan till etikprövningsnämnden men om det gick att göra skulle det vara bra.”
“Övrigt du vill ha sagt om AI?”
Den avslutande frågan gav alla chansen att skriva någon mer valfri tanke, vi kan ju ha missat någon fråga enligt de som svarade. En person tycker det borde erbjudas kurser, webinar och inspirationstillfällen i arbetsgivarens kurskatalog.
”Finns mängder av områden som skulle har stor nytta av AI – bara inte yrkesgrupper sätter sig på tvären och stoppar. AI måste in i vården och stötta”
En klok person opponerar sig lite mot att det är en teknik som letar efter ett problem, istället för tvärtom:
”AI är bra, vi skall använda dessa möjligheter…. Men, det blir lite konstigt när vi tar avstamp i en specifik teknologi som AI. Det vore bättre att utgå från de utmaningar som finns och sedan se hur vi kan lösa dem. Då kan AI vara ett värdefullt verktyg. Inte kasta teknik på verksamheten utan fokusera på det som kan förbättras…”
Det sista svaret vi vill lyfta upp handlar om den tekniktrötthet som finns:
”Som alla nyheter behöver man gå långsamt fram och förankra, det är viktigt att det kommer att finnas support på tekniska lösningar. All teknik strular och då måste vi ha supportfunktion. I nuläget har vi knappt support på de system vi har […] I ljuset av detta känns AI ganska långt bort.”
Idéworkshop för att reda ut möjligheter, hot och tänkbara lösningar
Som en komplettering till enkäten och för att ha grupper med bred representation tillsammans komma fram till sin syn på AI genomfördes en idéworkshop. Utöver att introducera till projektet och vad som skulle genomföras var det tre stycken arbetspass för de två grupperna med fyra deltagare vardera.
Deltagare var bland annat psykologer, läkare, projektledare med särskild kompetens inom AI, utvecklingsledare, en som forskar inom informatik och innovationsledare.
Första arbetspasset gick ut på att skriva ned på lappar allt man såg som möjligheter med AI och machine learning. För att ge grupperna lite starthjälp fanns exempelfrågor som:
- Vad kan AI / ML tillföra vården?
- Nyttor med AI och ”maskiner”?
- Hur kommer det patienten till godo?
- Vad inom ditt arbete skulle en maskin klara av?
Detta pass var tillfället att vara positiv. Något sånär landade alla lappar inom kategorierna diagnos, vårdmötet, behandling och övrigt.
Bland möjligheterna som skrevs på lappar återfanns bland annat:
- Patientsäkerhet genom automatiserad second opinion.
- Självtriage.
- Automatisera indata till journal.
- Utskrivningsbedömning IVA/slutenvård
- Automatisera patientkontakt och behandling.
- Jämlik och fördomsfri vård.

Bild 17: Möjligheter inom diagnosområdet.
Bild 18: Möjligheter kring behandling.
Det andra arbetspasset är den raka motsatsen. Det handlar om att gå på djupet med alla farhågor, lista sin oro för vad som kan gå fel och hot. En proaktiv krishantering, så man vet lite vilka frågor folk kan tänkas ha och på så vis förbereda sig åtminstone på dessa.
Även här hade vi ett antal exempelfrågor för att få fart på diskussionen.
- Vilka hinder finns?
- ○ För vården?
- ○ Patienten?
- Nackdelar med AI/ML?
- Vad innebär det att automatisera bort människor?
Grupperna redovisade på röda lappar. Till tredje och sista arbetspasset gick de loss på sina röda lappar i försöket att hitta lösningar på bekymren. I de fall man hade svar angavs vem som löser svårigheter, vad som löser och hur det går till.
Bild 19: Svårigheter kring strategi och teknik.
Svårigheter handlar om vad som försiggår i en AI. Är det en svart låda som inte kan granskas? Har vi tillit, och hur är det legala? Lite mer praktiska frågor handlade om att det saknas vision, strategi och att det är oklart vem som ansvarar för implementering av teknik.
Som tänkbara lösningar på problemen nämndes att utbilda ledningen och kärnverksamheten. Man ville också anlita AI-arkitekter och skapa ett kunskapscentrum. För att råda bot på tillitsproblemet behöver man hitta någon fungerande form av transparens. Det uttrycktes också en förhoppning om att man med smarta algoritmer skulle kunna tvätta till de datakällor som redan finns, för att de ska gå att använda till AI.
Slutsats – vad vill vi göra framåt?
Förutom att vi kommer fortsätta utforska ML resten av projekttiden (året ut) så har vi redan nu funderingar om specifika sidoprojekt vi avser påbörja om vi hittar rätt projektkompisar.
Vi tänker oss en eller flera av följande inriktningar framåt:
- Registerforskning + ML, tillsammans med forskare inom hälsometri på GU.
- Prediktera återinläggning. En inriktning som SU:s ePsykiatrienhet redan talat om. GU:s hälsometri kan tänkas erbjuda exjobbare.
- Transfer learning inom computer vision, exempelvis för bilddiagnostik tillsammans med radiologer.
- Computer vision: Träna ett eget VOC (Visual Object Classes) från något medicinskt. Har vi unik data i BFR? Kan ta flera månader eller åratal om man inte har rätt hårdvara eller lyckas parallellisera i större skala.
- Deep/transfer learning för att studera ansikten i jakt på diagnoser, egenvårdstips och självtriage i vardagen. Gäller att hitta en bra datakälla och nog med beräkningskraft.
- NLG (Natural Language Generation). Att beskriva mätvärden och annan icke-text med vanlig text eller få det uppläst. Är exempelvis en utmaning för de som ser dåligt att läsa tabelldata, eller för den som har svårt att förstå kan en beskrivande sammanfattning/slutsats hjälpa till istället för att man ska tvingas belasta sitt arbetsminne.
- NLP för att studera patientberättelser/anamnes, kanske med inriktningar som prioritering i vården. Här har vi redan en läkarkontakt på Sahlgrenska Universitetssjukhuset att samarbeta med.
- NLP för att automatisera skapandet av personliga sammanställningar av patientinformation från källor som 1177.se bland annat. Dessa råd skulle kunna efterfrågas via ett konversationsbaserat gränssnitt samt att man kan välja att få det sammanställda materialet uppläst eller inläst som en ljudbok.
- NLP: Undersöka om ordvektorer fungerar som teknik i ett vårdkontext.
- Övrigt: En sammanställning av medicinskt användbara; neurala nätverk som tjänst, nedladdningsbara ML-modeller som redan tränats upp, samt feature detectors. Finns några trovärdiga marknadsplatser för detta?
Vi ska ta möten med Chalmers innovationskontor, främst för att hitta lämplig matchning inom NLP/NLG. Det återstår att se vilka ytterligare parter vi väljer att samarbeta med.
Förutom att leta projektkompisar kommer vi leta efter finansiering genom att svara på lämpliga utlysningar.
Appendix
Allt är inte lämpligt att ta in i rapporten. Därför kommer här saker av karaktären att läsa mer nördiga detaljer.
Ordlista
Tänk på att några av orden i ordlistan har annan betydelse i andra sammanhang.
- Algoritm – ett sorts recept eller tillvägagångssätt som en maskin kan upprepa gång på gång.
- Amazon Echo (Alexa) – en smart högtalare man kan konversera med, ställa frågor till och be anteckna saker.
- Anamnes – berättelse om sjukdomshistoria, lite av en intervju som skrivs ner av vårdpersonal i mötet med patienten. Ett styrt samtal för att komma fram till lämpliga åtgärder.
- Apple Siri, SiriKit – Apples plattform för att konversera med deras prylar. Drar nytta av Apples servrar i bakgrunden för att förstå vad som sägs och användarens avsikt.
- Application Programming Interface (API) – ett sätt att prata med något tekniskt. Är ingången till en tjänst man hyr på nätet för bildigenkänning, exempelvis.
- Artificiell intelligens (AI) – att något artificiellt och skapat kan uppvisa ett intelligent beteende.
- Adaptive Boosting (AdaBoost) – en meta-algoritm för att komma fram till det mest troliga svaret av en mängd alternativ.
- Batch learning – att det neurala nätverket lär sig nya saker stötvis, med paket av nytt material att träna sig på. Jämför med online learning.
- Beslutsträd – ett strukturerat sätt att ta beslut. Tänk dig en trädstam som ingång och beroende på frågeställning blir några av de grövre grenarna aktuella. Ju mer information desto närmre ett löv kommer man. Lövet kan symbolisera en diagnos.
- Beslutstöd – att baserat på ett underlag av data få stöd att komma fram till ett beslut.
- Bias – att ha en snedvridning åt något håll. Används både om datakällor och de slutsatser man kan få genom machine learning. Ett exempel är Googles bildsök som visade sig fördomsfull när man sökte efter svarta tonåringar genom att visa dem i ett kriminellt sammanhang, medan vita tonåringar log och idrottade.
- Bild- och FunktionsRegistret (BFR) – världsunikt medicinskt register med bland annat röntgenbilder och annat från röntgenundersökningar. Driftas av Västra Götalandsregionen (VGR).
- Business intelligence (BI) – samlingsbegrepp för arbetet att bättre förstå sin egen verksamhet. Ofta genom att plocka fram data och ta beslut baserat på data istället för magkänsla/erfarenhet.
- Cascading classifiers – se Adaptive Boosting.
- Computer vision (CV) – att ge maskiner förmågan att se och tolka visuella ting som bild, video, etc.
- Convolutional Neural Network (CNN) – används oftast inom computer vision och är ett neuralt nätverk som för varje lager förfinar sitt intryck av exempelvis en bild. Det är alltså en beskrivning av hur samarbetet går till mellan nätverkets hidden layers.
- Deep learning (DL) – en specialvariant av machine learning där man använder många hidden layer och större komplexitet än annars.
- Entropi – ett kvantitativt mått på hur ordnad/strukturerad en informationsmängd är.
- Feature detection/engineering – engineering-delen handlar om att utveckla ett sätt att känna igen något, exempelvis ett öga i en bild. En “detector” är resultatet av engineering, alltså det som känner igen något visst. Feature detection är själva aktiviteten att försöka identifiera en eller flera saker.
- Generative Adversarial Networks (GAN) – två neurala nätverk som lär sig tillsammans. Den ena har rollen att försöka utmana den andra. Resultatet är ett nätverk som är bra på att skilja fejk från riktigt material och ett annat nätverk som är bra på att försöka luras.
- Github – utvecklartjänst du finner på github.com, där finns källkod, exempel på lösningar inom allt möjligt tekniskt.
- Google Home – Googles smarta högtalare, se också Amazon Echo.
- GPU (Graphic Processing Unit) – en grafikprocessor eller grafikkort. De är extra lämpliga för machine learning då de kan jobba med väldigt många saker samtidigt.
- Gränssnitt – ett sätt att interagera med något. Grafiska användargränssnitt (GUI) är det du har på mobilskärmen, att din mobil går att prata med är ett röstbaserat gränssnitt, att mobilen vibrerar för att berätta något är ett taktilt/haptiskt gränssnitt.
- Hidden layer – är normalt ett flertal lager i ett neuralt nätverk. De kallas hidden för att de inte är synliga på samma sätt som input- och output layer. Hidden layers är vad som avses när man pratar om en AI:s “svarta låda”.
- Hypotes – ett antagande om verkligheten, att man tror att något ligger till på ett visst sätt. Som att denna rapport tror att machine learning är användbart för att bedöma patienters hälsotillstånd.
- Input (layer) – input är det man stoppar in i ett neuralt nätverk, exempelvis en bild, input layer är det första lagret som tar emot bilden innan det “försvinner” in bland hidden layers.
- International Classification of Primary Care (ICPC) – ett av många kodverk som erbjuder koder för klassificering av olika åkommor i primärvården. Gör att diagnoser inte behöver skrivas med fritext. Har man tagit ett blodprov är det “-34”, medan feber har koden “A03”.
- ICD-10 – se kodverk.
- Kodverk – ett sätt att skapa struktur genom att ha koder som motsvarar exempelvis en diagnos, ett labbprov, eller liknande. Se International Classification of Primary Care för exempel.
- Kognitiva tjänster, cognitive computing – den mentala processen att ta till sig kunskap och förstå genom att tänka, uppleva och använda sina sinnen. Några leverantörer kallar sina tjänster kognitiva snarare än intelligenta eller gett dem en AI-stämpel.
- Kvalitetsregister – data som samlas in av vården för att följa upp vårdens kvalitet. Exempel på kvalitetsregister är dödsorsaksregistret, andra handlar om cancervården, m.m.
- KVÅ (Klassifikation av vårdåtgärder) – de koder som används vid rapporter till Socialstyrelsens hälsodataregister. Används för att sammanställa statistik över de åtgärder som hälso- och sjukvård utför.
- Latent Semantic Analysis (LSA) – används för att beräkna släktskap mellan ord eller begrepp. Ett sätt att låta en maskin upptäcka mönster, som att doktor och läkare i många fall tycks vara synonymt. Men också ett sätt att reda ut vad som inte tycks höra ihop, som att naglar och underliv i anatomiska sammanhang inte är särskilt besläktade.
- Länkade data, Linked Open Data (LOD) – ett sätt att strukturera information till en nivå att det närmar sig kunskap en maskin kan ta till sig. Jämför med hur en människa kan utforska Wikipedia.
- Machine intelligence – att en maskin visar intelligenta sidor eller kan bidra med insikter.
- Machine learning (ML) – att en maskin lär sig något utan att uttryckligen instrueras i detalj.
- Maskinläsbar – att en maskin kan ta till sig information. Kan visa sig vara ett problem när det krävs kognitiv förmåga att fylla igen luckor eller att ett dokumentformat visar upp innehållet korrekt men att det rent tekniskt lagrats lite huller om buller. Se också Länkade data.
- Modell, kunskapsmodell, Machine learning-modell (ML-modell) – den kunskap som paketerats genom processen att låta maskinen lära sig. Ibland brukar även det neurala nätverkets arkitektur ingå i modellen, som ifall antalet dolda lager, vilken ordning specialiserade lager har och så vidare.
- Målgrupper – se Personas.
- Named Entity Recognition (NER) – en teknik inom natural language processing för att arbeta med text, exempelvis att identifiera om en människa nämns i texten, om en diagnos nämns, eller dosering av läkemedel.
- Natural Language Generation (NLG) – att med teknik skapa en text eller något talat utifrån information. Kan vara en sammanställning som skrivs/talas baserat på insamlade data.
- Naturligt språkprocessering, Natural Language Processing (NLP) – paraplybegrepp för att bearbeta text och tal för att förstå innehållet. Se också NER, NLTK, NLU, mfl.
- Natural Language Toolkit (NLTK) – tekniskt ramverk som hjälper till vid arbete inom NLP.
- Natural Language Understanding (NLU) – att få en maskin att förstå naturligt språk och tal.
- Neurala nätverk, artificiellt neuralt nätverk (ANN) – en artificiellt skapat nätverk av neuroner som efterliknar en hjärna. Består av lager som input layer, hidden layers och output layer.
- Neuron – kan också kallas hjärncell eller nervcell.
- Online learning – till skillnad mot batch learning pågår ett ständigt lärande i det neurala nätverket. När någon säger att deras AI ständigt blir bättre lär det vara online learning det handlar om.
- Ordvektorer – en nyare lösning av det Latent Semantic Analysis försöker lösa. Ordvektorer handlar om att reda ut språkliga saker som vilka ord som verkar höra ihop, exempelvis fraser, ordspråk och liknande. Word2Vec är en sådan lösning som släppts fritt av Google.
- Output (layer) – output är själva svaret och output layer är det lager av ett neuralt nätverk där svaret kommer ut.
- Overfitting vs underfitting – overfitting är att dra för långt gående slutsatser baserat på den data man lärt sig av. En teknisk motsvarighet till fördomsfullhet. Underfitting är att inte se mönster som faktiskt finns där. Se också bias.
- Patientberättelse – fritt berättande om patientens hälsotillstånd, till skillnad från den mer strukturerade intervjun som sker vid en anamnes.
- Personas – ärketyper av de användare man vänder sig till med en lösning. De har ofta ett namn och en lista med beskrivande egenskaper för att påminna om vem som är slutanvändare.
- Procent, procentenhet – procent står för en förändring som är relativ till ett ursprungligt värde, medan procentenheter är en förändring av ett procenttal. Engelskans “per cent” motsvarar procent, en cent är en hundradels dollar eller euro. Exempel: om ett politiskt partis valresultat minskar från 25 % till 20 % av väljarnas röster har de tappat 20 procent av sina väljare (fem tjugofemtedelar), men samtidigt har de tappat 5 procentenheter.
- Region of Interest (ROI) – en avgränsad yta av exempelvis en bild, platsen för där något intressant eller värdigt att fokusera på finns.
- Reinforcement learning (RL) – en variant av machine learning där maskinen får försöka lära sig själv genom att veta vad som är ett önskvärt resultat (så kallad reward-funktion), samt vad den ska försöka undvika (så kallad cost-funktion). Jämför med att ta sig fram med cykel utan att cykla omkull.
- Second opinion – att få ett andra utlåtande kring något. Som att kräva att få en ny bedömning av sina röntgenbilder. Detta kanske kan automatiseras.
- Sentiment analysis – en NLP-teknik för att läsa ut känslor ur en textmassa eller något som hörs.
- Självförstärkande – att hamna i en rundgång av positiv/negativ förstärkning utan yttre/nya intryck. Som om en machine learning själv genererar data som den på nytt tar in som sin egen världsbild.
- SnoMED-CT – se kodverk.
- Supervised learning (SL) – att träna upp ett neuralt nätverk där den data man använder som kunskapsunderlag och innehåller facit (så kallade labels). I vårdsammanhang att man har anamnes och diagnoskod enligt en läkare. Se också unsupervised learning.
- Svart låda – avser det i ett neuralt nätverk som är svårt eller omöjligt att förklara exakt hur det fungerar.
- Synaps – det som binder ihop hjärnceller/neuroner och gör att de kan kommunicera som ett nätverk.
- Toy problems – inom AI används begreppet om lösningar på banala problem eller något det är svårt att se nyttan.
- TPU (Tensor Processing Unit) – en specialiserad processor från Google som designats för att vara bra på machine learning. Se också GPU.
- Transfer learning (TL) – att ta med sig lärdomarna från ett område och applicera på något annat. Exempelvis har neurala nätverk som tränats på blommor, djur och liknande visat sig ha en viss förförståelse som kan användas inom det medicinska när det gäller människor.
- Triage, självtriage – triage är bedöma och prioritera hur brådskande något är. På akuten behövs triage till att slussa förbi de riktigt allvarliga fallen medan att få de med mindre akuta tillstånden att slå sig ner i väntrummet. Om all kunskap om triage kan digitaliseras skulle man hjälpligt kunna triagera sig själv eller en närstående.
- Triageprotokoll – de kontrollfrågor, svar och observationer som behövs för att utföra en triage. Kan handla om att ta puls, observera andning eller sår, exempelvis.
- Turingtest – ett sätt att testa om en maskin lyckas få en människa den pratar med tro att maskinen också är en människa.
- Unsupervised learning (UL) – till skillnad från supervised learning har man bara en massa data, men saknar facit. Det innebär att man letar efter struktur i data, klassificerar och grupperar i jakt på något användbart.
- Valideringsdata, träningsdata – för att träna upp en maskin delar man upp sin datakälla i minst två olika grupper. Träningsdata är det som används för att träna upp maskinen och är normalt sett lejonparten av den ursprungliga datakällan. För att kunna bedöma hur pricksäker maskinen är på att förutspå något har man sparat undan lite valideringsdata som maskinen inte vet något om. När man sedan matar sin upptränade maskin med ny data kan man mäta hur bra den presterar – hur bra dess “fitting” är. Se också overfitting.
- Visual Object Classes (VOC) – beskriva visuella objekt som bilar, människor, köttbullar, svårläkta skrapsår och leverfläckar som behöver åtgärdas. När det gäller det icke-medicinska finns en visuell motsvarighet till Turingtestet, en tävling för att se om en människa eller maskin är mest pricksäker på att identifiera objekt.
- Vitalis – årlig konferens i Göteborg kring ehälsa, vårdteknik, etc.
- Weak classifiers – faktorer som var och en inte har en stor betydelse för resultatet, men som tillsammans kan fälla avgörandet vad något är. Som att spetsiga öron, morrhår och låg mankhöjd mer troligt är en katt än en hund.
- WEIRD – begrepp inom psykologin, förkortning av Western, educated, industrialized, rich and democratic. Pekar på utmaningen att de som utformar algoritmer inte alltid har jättemycket gemensamt med alla sina användare.
Fördjupande material
Artiklar:
- 450,000 Women Missed Breast Cancer Screenings Due to “Algorithm Failure”
- AI winter is well on its way – kritik mot de som översäljer de framsteg som görs inom AI
- Using electronic patient records to discover disease correlations and stratify patient cohorts, om att se korrelation och interaktion mellan olika läkemedel
- Patient stratification and identification of adverse event correlations in the space of 1190 drug related adverse events
- Data is not the new oil (Techcrunch)
- IBM outlines the 5 attributes of useful AI
- Is AI Riding a One-Trick Pony? Att vi utan backpropagation inte skulle brytt oss om AI idag
- The replication crisis – svårt att återskapa/replikera fynd inom AI/ML
- How to jump start your deep learning skills using Apache MXNet – om deep learning och NLP
- Algorithm can predict if you’ll live after a heart transplant with scary accuracy – algoritm är 14% bättre än nuvarande kunskap
- Why is machine learning ’hard’? Beror på att man har två ytterligare lager att felsöka jämfört med övrig mjukvaruutveckling
- 300 000 gånger mer data i AI-modeller – specialiserade processorer (GPU:er och TPU:er) gör att det går att utföra beräkningar på mer data, mängden har fördubblats var 3,5 månad sedan 2012 enligt artikeln
- Word2vec – om en lösning för att reda ut vilka relationer som finns i text, som vilka ord som ingår i fraser, ordspråk eller andra sorters mönster som att för- och efternamn ofta följs åt i en text
- Data science – för att ta bättre beslut– om datadrivna beslut
- Grandmother cell – Wikipedia – vi har specialiserade hjärnceller, bland annat för att snabbt känna igen mormor
- The Guardian view on AI in the NHS: a good servant, when it’s not a bad master – perspektiv på att samla in data
- A Guide to Successful AI Implementations, and Why So Many Fail – hur riggar du ett AI-projekt och lär av de som misslyckats
- Gender shades – How well do IBM, Microsoft, and Facebook AI services guess the gender of a face?
- Hur pass intelligent är AI, egentligen? En orientering i ämnet AI
- FairML: Auditing Black-Box Predictive Models – att kunna inspektera ML-modeller
Böcker:
- Machine Learning Yearning av Andrew Ng
- Data Science for Business: What you need to know about data mining and data-analytic thinking av Foster Provost och Tom Fawcett:
- Our Final Invention: Artificial Intelligence and the End of the Human Era av James Barrat
Tekniska lösningar:
- Apache MXNet som skalbar miljö för lärande så data inte lämnar organisationen
- fitchain.io
- FairML – ramverk i Python för att hitta bias i machine learning
- IBM:s Bluemix stödjer delvis svenska inom NLP – keywords, metadata och entities
Videoklipp, demo & poddavsnitt:
- 2D Visualization of a Convolutional Neural Network – provkör lösning för igenkänning av siffror
- Hello World – Machine Learning Recipes #1 – koda en egen machine learning på cirka fem minuter
- Neural Network 3D Simulation – visualisering av bildtolkning i flera lager av neuralt nätverk
- Reproducibility and the Philosophy of Data med Clare Gollnick i TWiML Talk
- The no free lunch theorems av Data Skeptic
Datakällor & övrigt:
- SND – Svensk Nationell Datatjänst för att orientera sig i de forskningsdata som finns
- Öppet API för Försäkringsmedicinskt Beslutsstöd, från Socialstyrelsen
- Watson Data Kits – av IBM färdigtvättade och strukturerade data inom ett antal olika branscher
- PASCAL VOC (Visual Object Classes) – exempel på visuell mönsterigenkänning
- High Performance Computing (HPC) in the Cloud | Accelerated Computing – om att hyra beräkningskraft som en tjänst
Projektets delrapporter i utvecklingsbloggen
Delrapporter i kronologisk ordning från utvecklingsbloggen.
- AI-projekt under uppstart – inventering av produktifierade tjänster – vi började med att testa vad leverantörerna erbjuder
- AI: Naturligt språkprocessering förstärkt av svartkonst – om NLP
- AI-projektet: Prototyp på app för smartklocka – exempel på demonstrator av slutlig lösning
- AI-projektets informationsarkitektur – om den datakälla vi inspekterat med anamnes och ICPC-koder med diagnoser
- Att konversera med maskiner – hur mycket förstår dessa maskiner vad man säger?
- GAN tränar en maskins förståelse genom att duellera sig själv – att låta en maskin lära sig själv
- Deep learning till beslutsstöd för att klassificera tecken på stroke? – klassifikation av ett ansikte uttryck
- AI och computer vision för att bli mer redo för GDPR – om klassificering av objekt
- Idéworkshop om möjligheter, svårigheter och lösningar – workshop där olika personer verksamma inom vården bidrog
Tack till
De som korrekturläst eller bidragit med tips på innehåll. Särskilt tack till:
- Agneta Grangård
- Kerstin Hinz
- Almira Thunström
- Kristian Norling
- Stuart Filshie
- Martin Adiels
Källhänvisningar
- sv.wikipedia.org/wiki/Artificiell_intelligens
- sv.wikipedia.org/wiki/Maskininlärning
- sv.wikipedia.org/wiki/Sjukdomshistoria
- en.wikipedia.org/wiki/Natural-language_processing
- en.wikipedia.org/wiki/Named-entity_recognition
- en.wikipedia.org/wiki/International_Classification_of_Primary_Care
- sv.wikipedia.org/wiki/SNOMED_CT
- sv.wikipedia.org/wiki/ICD-10
- www.socialstyrelsen.se/klassificeringochkoder/atgardskoderkva
- en.wikipedia.org/wiki/Natural_Language_Toolkit
- sv.wikipedia.org/wiki/Deep_learning
- sv.wikipedia.org/wiki/Länkade_data
- api.socialstyrelsen.se/fmb/dokumentation/psi/swagger-ui.html
- www.dyslexiforeningen.se/vad-ar-dyslexi/
- en.wikipedia.org/wiki/Feature_detection_(computer_vision)
- en.wikipedia.org/wiki/Convolutional_neural_network
- sv.wikipedia.org/wiki/Triage
- en.wikipedia.org/wiki/Decision_tree
- en.wikipedia.org/wiki/Weak_AI
- computersweden.idg.se/2.2683/1.698148/it-kopare-ai
- en.wikipedia.org/wiki/Turing_test
- en.wikipedia.org/wiki/Business_intelligence
- en.oxforddictionaries.com/definition/intelligence
- en.wikipedia.org/wiki/How_to_Lie_with_Statistics
- en.wikipedia.org/wiki/Artificial_neural_network
- www.scientificamerican.com/article/one-face-one-neuron/
- en.wikipedia.org/wiki/Supervised_learning
- en.wikipedia.org/wiki/Labeled_data
- en.wikipedia.org/wiki/Unsupervised_learning
- en.wikipedia.org/wiki/Reinforcement_learning
- en.wikipedia.org/wiki/Transfer_learning
- en.wikipedia.org/wiki/Kullback–Leibler_divergence
- en.wikipedia.org/wiki/Diversity_index
- en.wikipedia.org/wiki/Online_machine_learning
- en.wikipedia.org/wiki/Sentiment_analysis
- www.chalmers.se/sv/institutioner/cse/kalendarium/Sidor/Thesis-Defence-Olof-Mogren.aspx
- en.wikipedia.org/wiki/AdaBoost
- en.wikipedia.org/wiki/Cascading_classifiers
- en.wikipedia.org/wiki/Latent_semantic_analysis
- en.wikipedia.org/wiki/Latent_semantic_analysis#Applications
- developer.infermedica.com/docs/nlp
- www.gu.se/omuniversitetet/personal/?languageId=100000&disableRedirect=true&returnUrl=http%3A%2F%2Fwww.gu.se%2Fenglish %2Fabout_the_university%2Fstaff%2F%3 FlanguageId%3D100001%26userId%3Dxrawar&userId=xrawar
- aiweirdness.com/post/171451900302/do-neural-nets-dream-of-electric-sheep
- twitter.com/picdescbot
- en.wikipedia.org/wiki/Boosting_(machine_learning)#Boosting_algorithms
- en.wikipedia.org/wiki/Feature_engineering
- scapis.se
- techworld.idg.se/2.2524/1.703287/nvidia-hgx2
- well.blogs.nytimes.com/2016/03/14/hey-siri-can-i-rely-on-you-in-a-crisis-not-always-a-study-finds/
- vgrblogg.se/utveckling/2016/09/09/jamlik-vard-i-algoritmernas-varld/
- rationalwiki.org/wiki/WEIRD
- spectrum.ieee.org/riskfactor/computing/it/450000-woman-missed-breast-cancer-screening-exams-in-uk-due-to-algorithm-failure
- theflatearthsociety.org
- vgrblogg.se/utveckling/2018/03/21/prototyp-pa-app-for-smartklocka/
- github.com/Vastra-Gotalandsregionen/health-guide-for-apple-watch
- github.com/marcusosterberg/triage-at-home/blob/master/Triage-at-home.ipynb
- github.com/marcusosterberg/triage-at-home
- en.wikipedia.org/wiki/Natural_language_generation
Omslagets bakgrundsbild är designat av starline / Freepik